
Stambia component for Big Data Hadoop
Apache Hadoop is an open source framework of distributed storage and processing of very large sets of data across clusters of computers. Hadoop ecosystem consists of a collection of softwares for different purpose. These are HDFS, HBASE, Hive, Impala, Sqoop and many more.
Integrating your data to Hadoop ecosystem, is commonly adopted to handle big volumes of data and variety of data and using the right tools to do that is very important for a successful implementation.

Hadoop Adoption: What's important to note
Challenges in your Hadoop journey
Many organizations face challenges, often, in moving to Hadoop based platforms. Some of these are:
- Inadequate skill-set to implement software and hardware strategies
- Lack of tools that can reduce manual coding and redundant efforts needed to set-up integration processes
- Longer learning curve of the existing team to get trained on Hadoop platform
- Inability to utilize the platform efficiently to reduce cost and gain maximum performance
- Risk of exposing sensitive and confidential data due to lack of data privacy processes
To overcome above challenges, it is important to choose the right tools to accomplish your projects successfully. These tools should reduce manual coding and automate workflows, to simplify the day to day needs.

Harness the power of Hadoop

Traditonal tools, though provide the capabilities to work with Hadoop platform, were originally not built keeping them in mind. They have adapted themselves to provide an ELT-ish component for Hadoop Integration.
Hadoop based plaform, scales linearly and supports a wide range of analytics processing techniques.
When Integrating your data in hadoop, its important to use pure ELT solution that can use these capabilities to the most to get the best performance out of it.
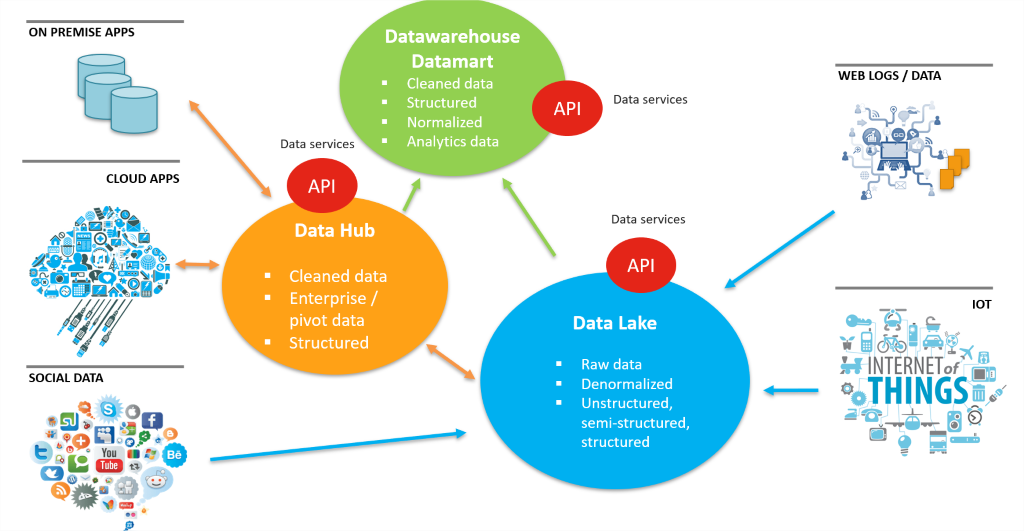
Hadoop based Datalake Projects
Data Lake Initiatives involves handling a greater size and diversity of data from various types of sources. As well, this data, then needs to be processed, repurposed. Hadoop has become the most commonly used platform enabling companies to set-up a Data Lake.
With a vast variety of open source softwares in the Hadoop ecosystem, IT teams can set-up the Data Lake arrhitecture. An essential part is setting your integration pipelines, that feeds the Data Lake. The integration layers should be able to cater to different data needs, in terms of the volume, variety and velocity.
The ability to handle different kinds of data formats, data technologies, and applications is very important.
The best case scenario is when you do not have to use to multiple integrators so as it to keep the integration layer consistent and easy to manage.
Data Security concerns

As Hadoop adoption is rising, more and more organization feel the need to have more security features, given that the focus inititially, was on handling and processing big volumes of data.
With the introduction to the commercial distribution model from software vendors like Cloudera, we can see more security features added. Significant changes have been made to the Hadoop authentication, with Kerberos, where data is encrypted as part of the authentication.
Integrating the data should not only leverage from these security features, but also provides wide variety of solution to deal with regulations such as GDPR to allow data masking in Hadoop.
TCO of you Hadoop Implementations
One of the key advantage of moving to a Hadoop ecosystem is that not only you gain the ability to process vast variety and huge volumes of data, but you can do that in a fraction of cost when compared to the traditional database systems.
Similarly as this should also be applied on the Integration tools that would be used, just so as to have a better control on the global cost of your projects.

Features of Stambia Component for Hadoop
Stambia Component for Hadoop, provides various capabilities for users to Integrate their data and move to Hadoop based plaforms with ease. There is no manual coding required and with the use of the Designer Workbench, users can perform data mappings the same way as they do with any other technology like when working with RDBMS, flat files etc.
This is possible through the Hadoop Templates that are specifically designed for each software in the Hadoop ecosystem. These templates not only reduces the need to write manual codes, but also gives you the possibility to evolve your integration processes with time.
-
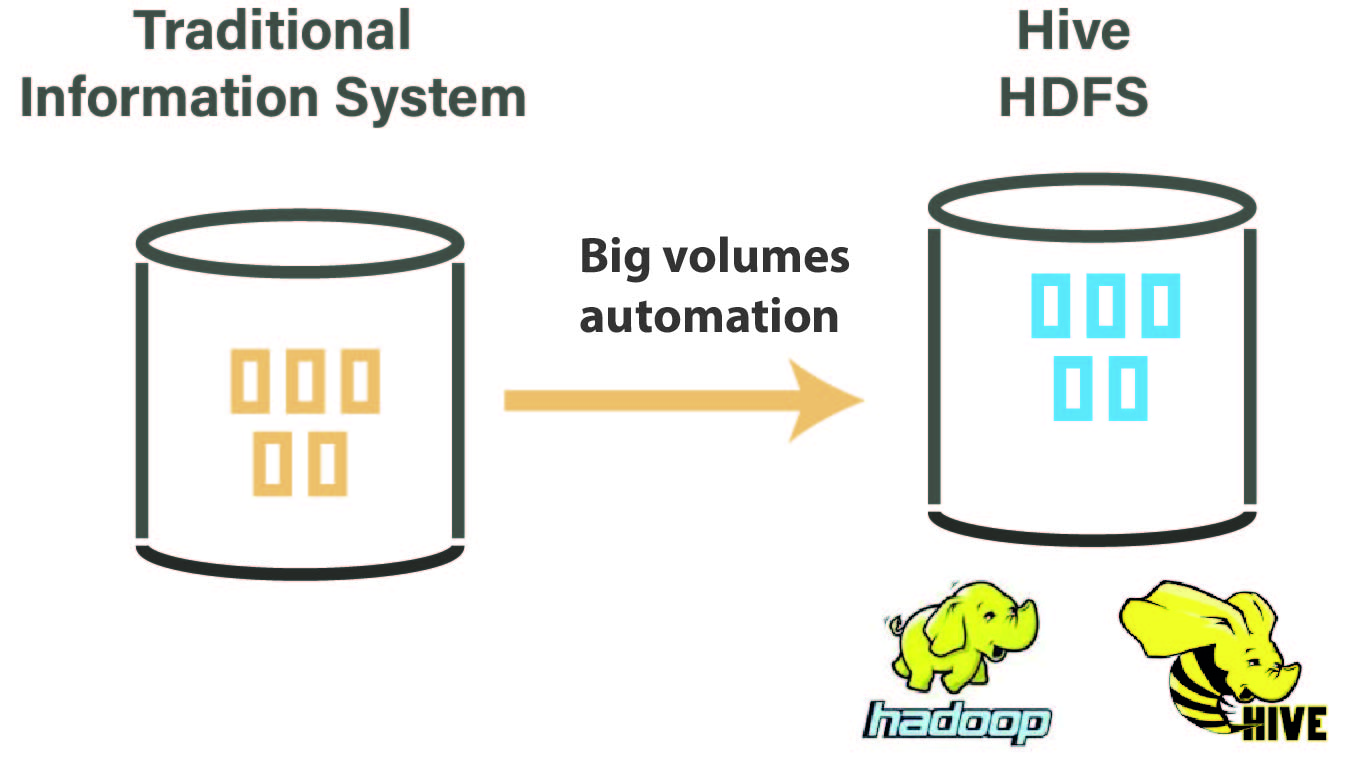
HDFS – It's very important to automate the process of moving big volumes of data to the Hadoop Dristributed File System and with a few drag n drops, you can do that in Stambia, with the help of HDFS templates, that can help you in moving data to and from HDFS. These templates can be plugged anywhere based on the integration requirement for e.g. RDBMS to HDFS, HDFS to Apache Hive etc.
-
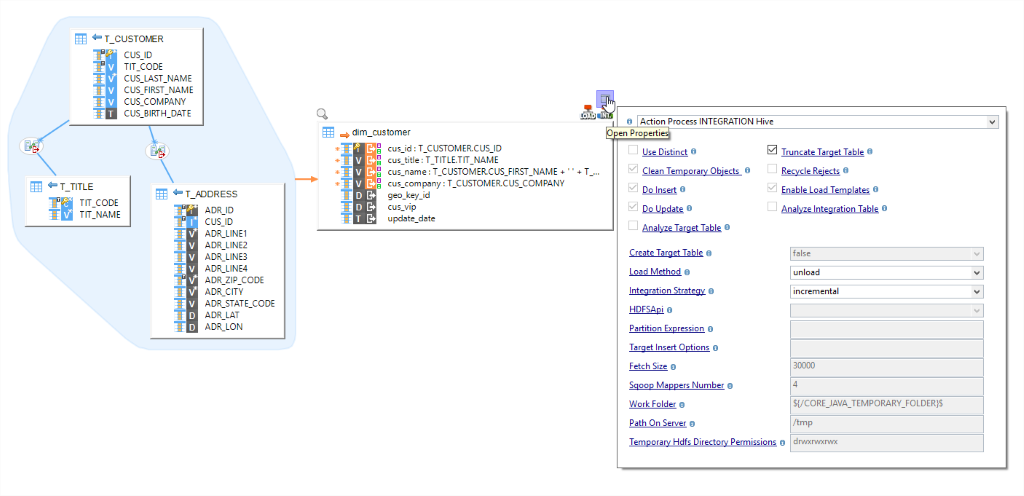
HIVE – Design mappings to move data to and from Hive the same way as you would do in case of an RDBMS. Perform HiveQL operations and choose quick template options to decide the integration strategy and optimized Methods.
-
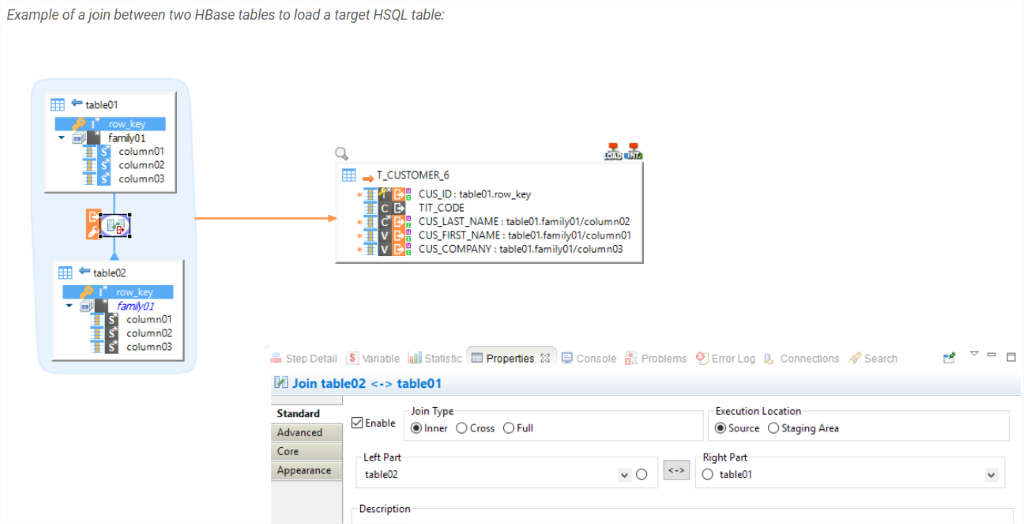
HBASE – Work with NoSQL database with ease. No specialized hands-on knowledge to begin with, as Stambia templates for HBASE take care of all the complexities. As a user you just provide the drag n drops and choose the integration strategy, or extract data out of HBASE performing quick joins by a simple drag n drop.
Apart from these, a host of dedicated templates for Sqoop, Cloudera Impala, Apache Spark etc. are available for users to be able to define their integration process using the appropriate softwares in their Hadoop ecosystem.
Stambia: Model Driven approach to increase productivity, ELT approach to increase performance
Stambia being a pure ELT tool is suitable for setting up integration processes when working with Hadoop ecosystem. What Stambia brings in, is a Model Driven Approach, which helps users automate a lot of redundant step that involves manually writing code. This way users just connect and work with their metadata and design simple mappings and choose, certain configurations/options. On execution, the code is automatically generated in the native form and executed.
The templates that contain the complex code can be accessed by the user and can be modified/enhanced at any time without any constraints.
In short, you use a tool that not only expedites your integration set-up, shortens your development cycle, but also provides you an integration platform that can be tailored to any technological or business requirement changes.

Stambia: Unified solution for your Data Lake projects
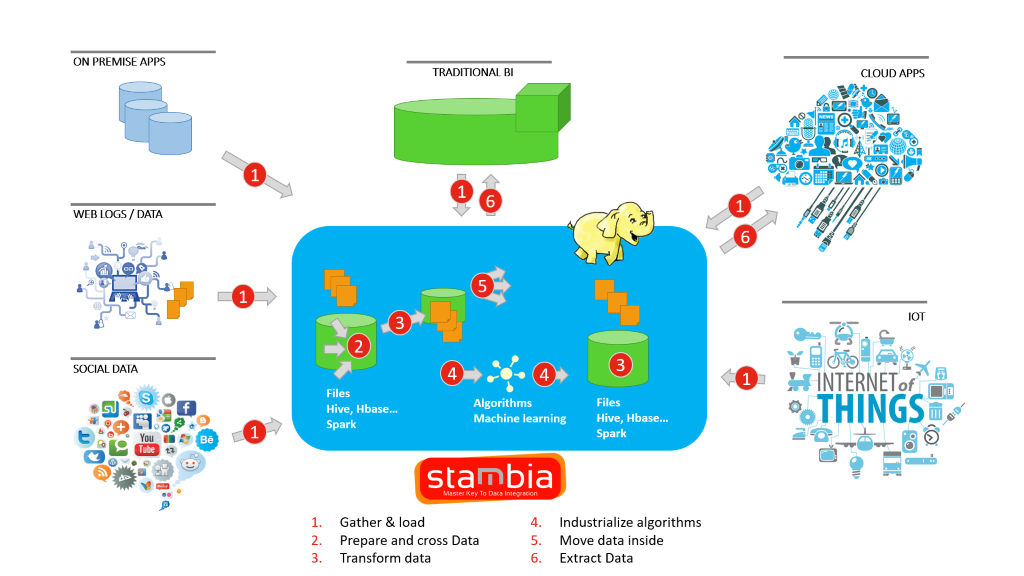
Stambia is a unified solution, which most importantly helps organizations and their IT teams to build the integration layer without dealing with multiple softwares and solutions, with different designing methods and various licensing implications.
Since, in a Data Lake, integrating various types of structured, semi-structured and unstructured data is needed, by using a single integration platform, the focus remains on the Data Lake Architecture, rather then the complexities that come with multiple integration solutions.
Stambia also provides the flexibility that is needed to customize for any open source technology or other requirements.
Stambia: Integration in a secure mode
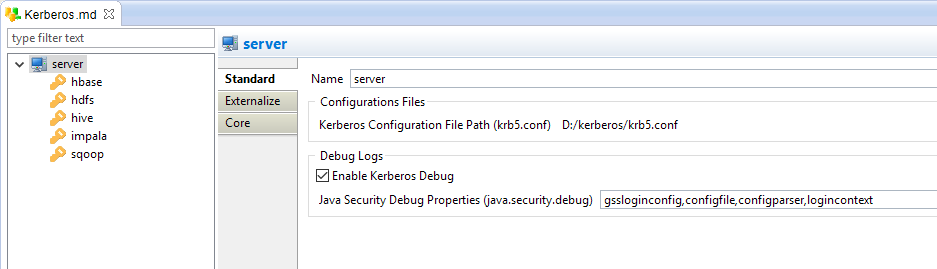
Stambia components for Hadoop supports Kerberos authentication and is easy to set-up on any of the technologies with just a drag n drop. All the Kerberos properties can be defined so as to have a secure access to the data in Hadoop, when integrating.
Another aspect is the data privacy protect, or GDPR regulations, which is becoming very important for a lot of organizxations. Stambia has a component for GDPR, where users can Annonymize and Pseudonymize their data.
In order to know more about privacy protection, take a look at a video about our "Privacy Protect tool":
Hadoop is a low-cost platform and so should be the Integration layer
At the end, the integration layer cost with Stambia in your Big Data projects will remain transparent and easy to understand. Stambia pricing model remains pretty simple and agnostic to the kind of projects, data volumes, number of environments etc.
Stambia being an E-LT doesn't have any specific hardware pre-requisites and due to it's ease of use, the learning curve is very short. Therefore, going in to your Hadoop based Big Data projects, you have a clear visibility of your TCO.

Technical specifications and prerequisites
| Specifications | Description |
|---|---|
|
Protocol |
JDBC, HTTP |
|
Structured and semi-structured |
XML, JSON, Avro (coming soon) |
|
Hadoop Technologies |
Following dedicated Hadoop connectors are available:
|
| Connectivity |
You can extract data from :
For more information, consult the technical documentation |
|
Storage |
The following operations can be performed on HDFS directories:
|
| Data loading performances |
Performances are improved when loading or extracting data through a bunch of options on the connectors allowing to customize how data is processed such as choosing which Hadoop loaders should be used. For performances enhancements, the connectors support using the various utilities such as loading data into Apache Hive or Cloudera Impala directly from HDFS, from Sqoop, through JDBC, ... |
| Stambia Version | From Stambia Designer s18.3.8 |
| Stambia Runtime version | From Stambia Runtime s17.4.7 |
| Notes |
|
Want to know more ?
Consult our resources



Did not find what you want on this page?
Check out our other resources:
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration