
ETL vs ELT: Maximize your performance and reduce your integration costs
"We're entering a new world in which data may be more important than software.." Tim O'Reilly
Digital transformation and exploding numbers of new applications have transformed the vision of data within Information Systems.
New challenges have emerged:
- Diversity of data sources (Cloud, SaaS, IOT: Internet of Things, Internet)
- Increasing data volumes needing to be processed (Big Data, Social Networks, Web)
- Appearance of new types of data (unstructured "text, audio, video, images", non-hierarchical "NoSQL, Cluster")
How to quickly ingest, clean and transform this mass of data?
How to control integration costs and preserve infrastructure investments?
Why are traditional ETL solutions no longer in line with the current challenges?
Stambia Enterprise relies on a different approach called "delegation of data transformations", also called ELT approach. Discover the key differences between the former ETL world and the ELT vision.
What are the benefits of the ELT approach?

Traditional ETL confronted to the challenges of digital transformation
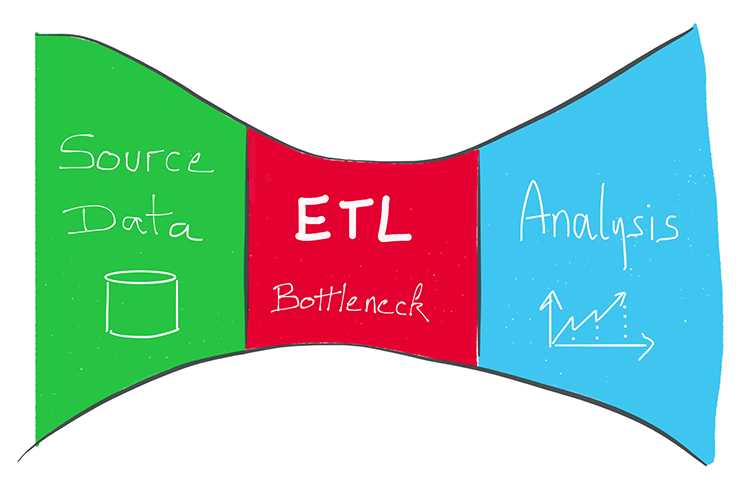
ETL: What is an ETL?
ETL (Extract, Transform, Load / "Load") appeared in the 80s.
They are software that address data transformation needs between sources and targets: Aggregate and store different types of data from multiple sources into a target database.
The tools based on this logic generally have a dedicated and proprietary engine, and are installed on separate servers.
They have a centralized view of data transformation. All treatments and data transformations are done through the ETL engine.
Examples of some traditional ETL: Informatica, Cognos decisionStream, SSIS, DataStage, Talend, Genio
ETL: What are the challenges of traditional ETL tools?
"Data volumes are exploding faster than ever, and by 2020, about 1.7 megabytes of new information will be created every second for every human being on the planet."
With so much data being generated every second, the need to extract, transform, and load (store) this data into third-party systems, and then extract useful information, has become a necessity for every business.
However, by using a dedicated transformation engine, the traditional ETL tools on the market are facing the following limitations when managing large volumes of information:
- Bottleneck effect:
- The more data flows are developed, the more the engine usage becomes important
- This can be penalizing in terms of performance
- This is generating an important network traffic
- This type of architecture can be expensive because of:
- The cost usually related to the power of the transformation engine (billing based on processors, for example)
- The cost of the resources used (the larger the volume of your data will be important and the more dedicated resources will be needed)
- The need to physically locate the transformation engine:
- Cloud Architecture: Data needs to pass through the engine.
- Hadoop architecture: same observation
30-40%: estimate of the volume of data created each year
Small illustration about the limits of the ETL approach
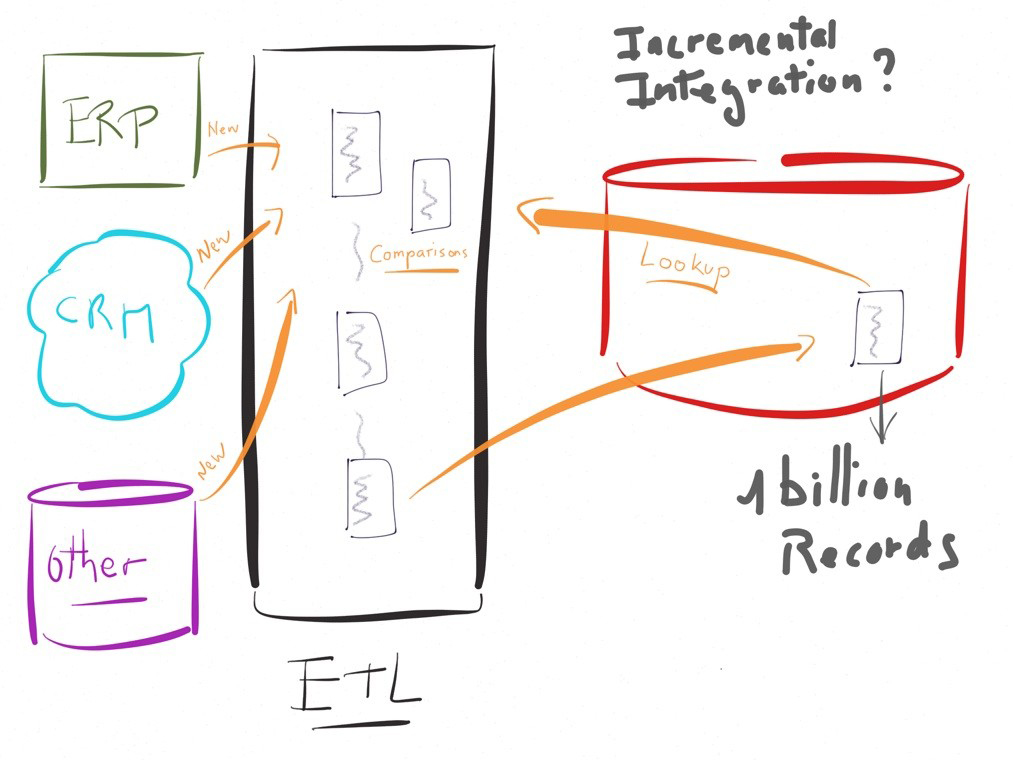
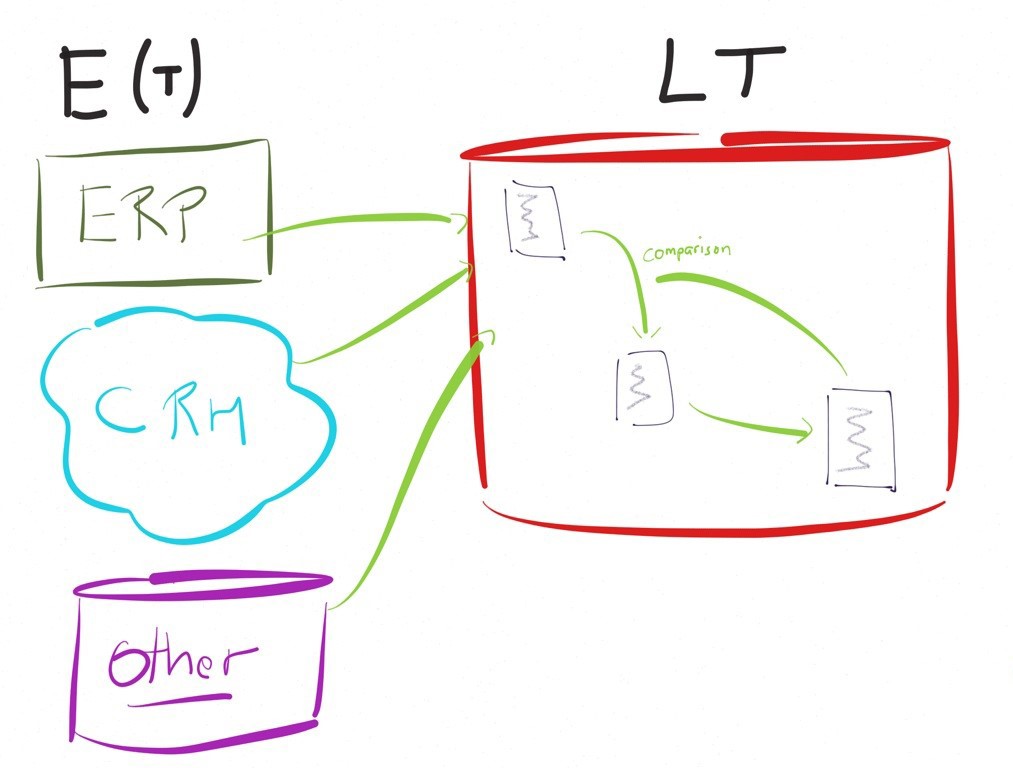
To be convinced of the performance issues of an ETL approach let's take a concrete example.
Imagine feeding a business intelligence database. Let's say a table in a target, already containing millions or billions of records cumulated over time.
The incremental feeding of this target from a few thousand new records from the source (that is, updating only the source changes since the last run) will require a comparison of the new records from the source with existing records in the target.
In a traditional transformation engine-based approach, the execution would look like the diagram on the left, involving lookup (or equivalent) features to compare the data. This lookup will deal with billion or million of records.
Very often, in this example, the performance will be an important challenge.
In such a case, in order to be performant, the traditional ETLs will disavow their "engine" logic by executing instructions on the databases rather than on their own system.
Delegated approach of transformations (ELT), what is it?
ELT Definition
The ELT approach (delegation of transformations) takes advantage of existing information systems by having the technologies already in place (underlying technologies) do the transformation work, rather than using a separate proprietary engine.
The transformations are carried out by databases or other technologies (Hadoop cluster, cloud cluster, MOLAP systems, operating systems, etc.).
Extractions and integrations of data can be realized through existing native and performant tools on these technologies.
In this architecture the load is distributed among the different systems: the ELT is based on a non-centralized architecture unlike the centralized ETL approach.
The timing and location of the transformation are the two key elements that characterize an ELT approach.
A simple illustration of the benefits of an ELT approach
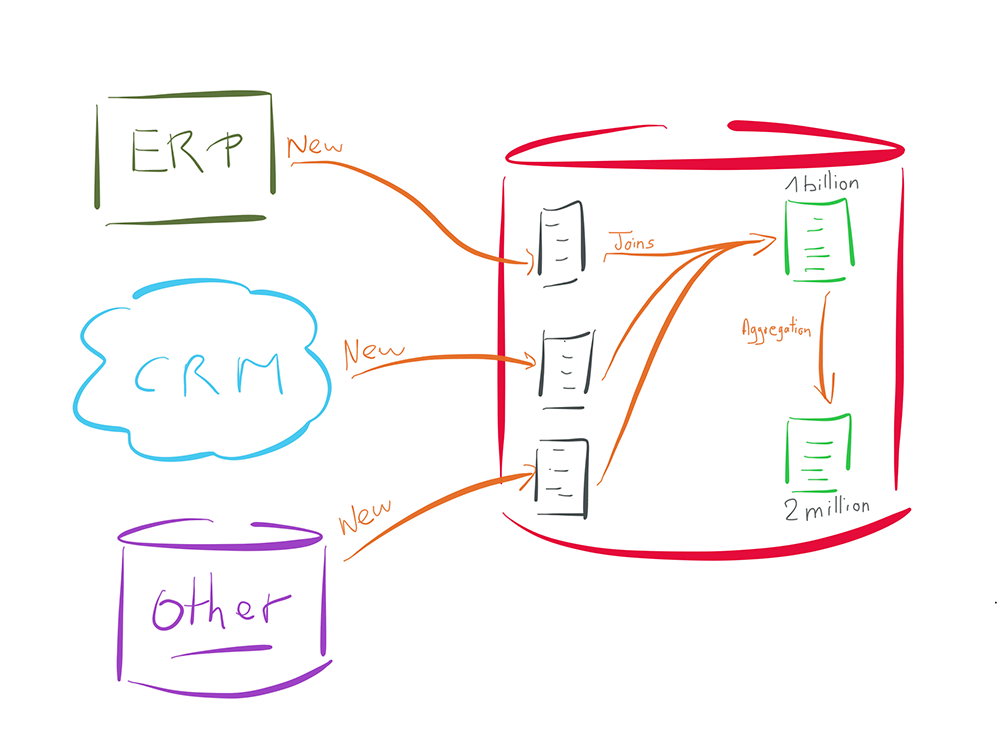
Let's take the above example of the ETL approach but now with an ELT.
In the previous example above we had to collect a few thousand "new" source records, then compare them to 1 billion data already existing in the target.
The ELT approach will consist in loading the few thousands of new source data inside a temporary space on the target database side (the three tables in gray in the schema).
The comparison will then be done directly within the target database, without requiring any look-up operations or other expensive operations for the database.
Indeed, the latter will use its indexes or other internal mechanisms, which are optimized for this type of operation.
Likewise, once the data has been integrated into the target table (the first green table at the top of the schema), any aggregation operation to another table within the same database (the second green table of the schema) will only need actions inside the database (no external engine needed outside of the database).
For which use case is the ELT approach better?
ELT architecture, best approach for cloud projects and hybrid architectures?
As stated above, an ETL approach requires the use of a transformation engine. What is happening with applications hosted in the cloud? Where will the engine be located?
The use of the cloud is rarely at 100%. So, this implies, in an ETL approach, the need to install multiple engines (on-site and in the cloud) to handle the different cases.
The situation is much more complicated in multi-cloud architectures (Amazon, Azure, Google ..., Salesforce, Oracle ...): Should we install multiple ETL engines? Should we invest in specific Cloud ETLs, and lose the ability to rationalize and govern data?
In contrast, the choice of an ELT approach works in all use cases , because it does not require the installation of proprietary engines. It will make the underlying technologies do the work and will have a very light footprint on the systems.
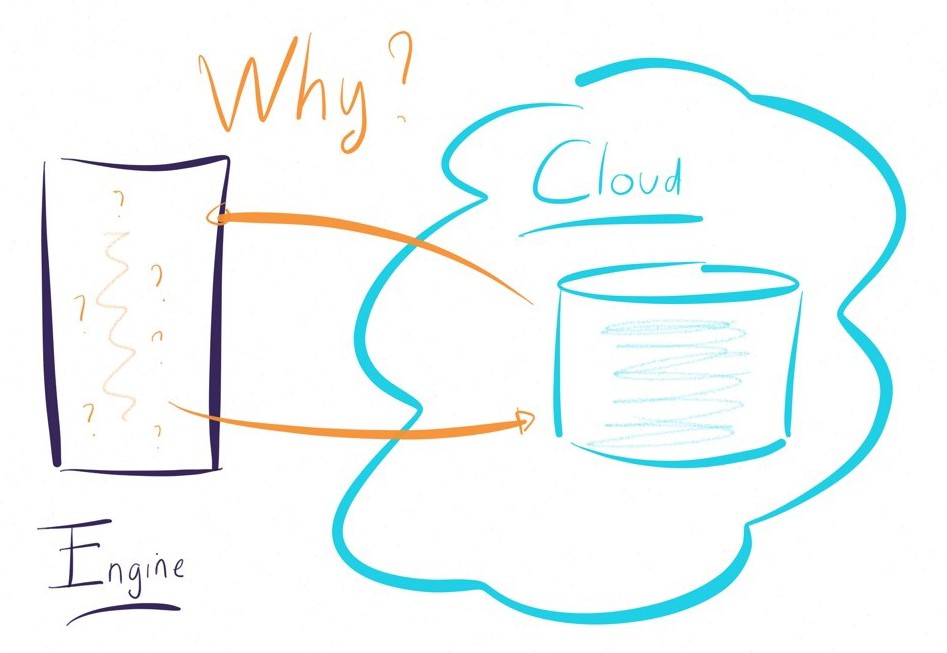

The advantage of choosing an ELT over an ETL for your Big Data projects
The hadoop (Big Data) based infrastructure is developed to transform large volumes of data and to help companies manage complex cases.
Why add an intermediate layer (engine) to manage this data?
The ELT approach will allow the data transformation and algorithms complexity to be delegated to these powerful platforms (Hadoop, Spark and Big Data).
The ELT approach, champion of large data volume handling?
The ELT approach minimizes the use of intermediate resources (server, network, disk ...).
It also guarantees a perfect usage of the native and powerful functions of existing environments (file loader, database transformation capability or Big Data environments).
The ELT approach avoids taking data out of their environment to be processed by an external engine.
Take the example of aggregating a set of data within a database.
Thanks to the delegation of transformation approach (ELT), there will be no requirement for using an external engine.
The data will remain in its own environment.

The benefits of using an ELT solution for your data integration projects
Summary of the benefits of the ELT
The ELT approach allows to:
- Maximize performance
- Effective: no intermediate technologies
- Fast: native communication with existing technologies
- Simplify and rationalize the architecture
- Not intrusive: no additional system to install
- Distributed: the load can be smoothed over the different systems.
- Optimize the use of existing technologies
- Cost-effectiveness: the available power of existing systems is used
- Better experience : Customer's knowledge and control of the existent technologies are consolidated
- Cost-reduction: Reduce the infrastructure costs and capitalize on your investments
- To be naturally evolutionary
- Automatic Scalability: The available power of the underlying systems is used. If they evolve, the ELT benefits from it.
- Fast Deployment: Adding sources or targets does not require adding engines. The tool is operational immediately.

Benefits of the Stambia ELT
A top down approach, designing with the universal data mapping
An ELT is interesting only if it makes it possible to simplify the work of the developers by abstracting the underlying technologies and giving them a more business oriented view.
In this sense, Stambia's universal data mapping vision makes the ELT mode accessible, without the need for advanced technical knowledge.
The top down approach allows to develop by focusing on the business rules, and let Stambia generate the transformations on the appropriate platforms. This automatic generation will be made using the best practices on these technologies, in order to guarantee the best levels of performance.
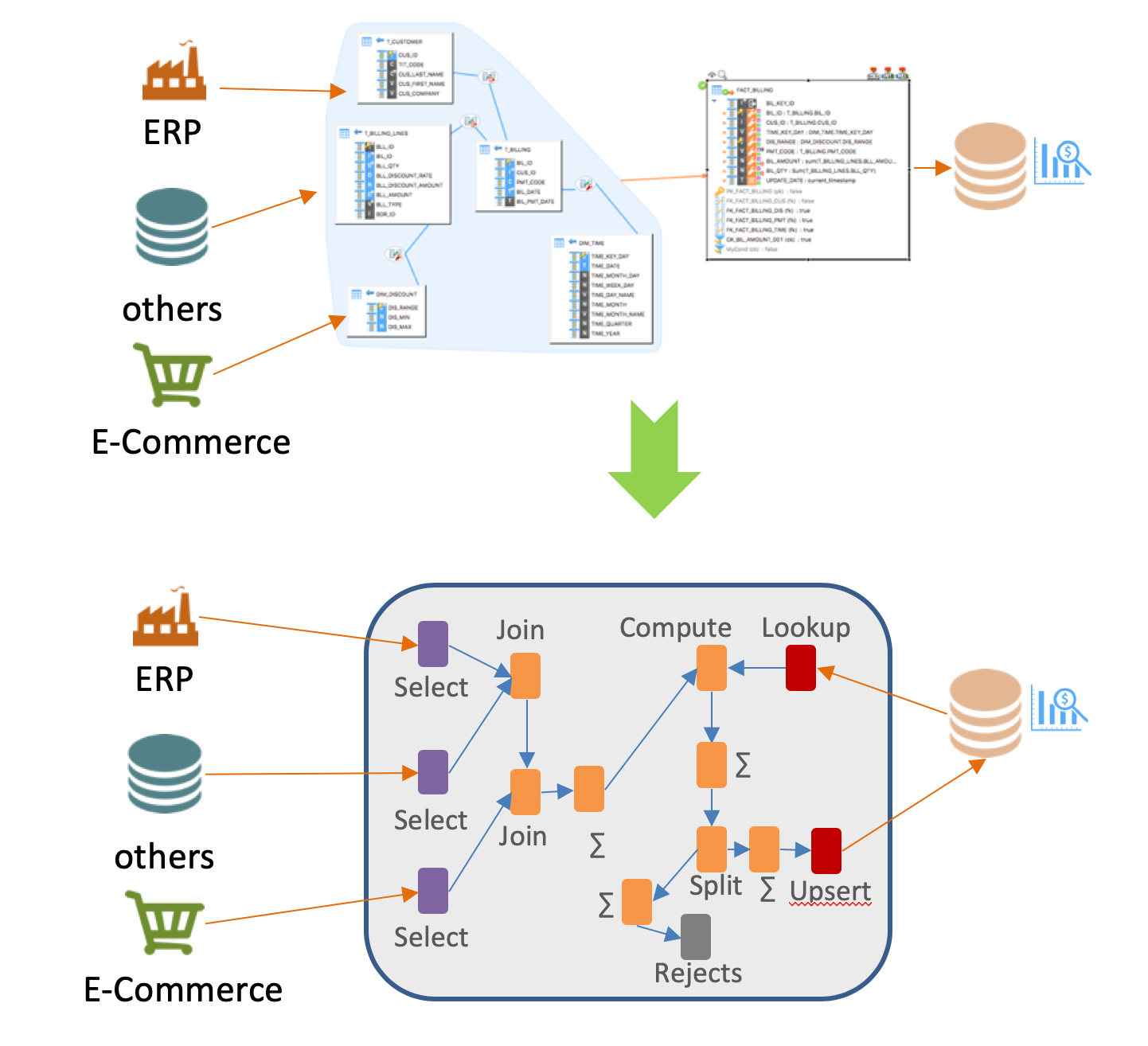

A fully customizable and self-adapting solution
Since the ELT approach aims to optimize the use of existing technologies (databases, servers, clusters, etc.), it is important that the ELT can easily and quickly adapt to technical evolutions.
This is only possible if the ELT platform is made for this.
Stambia is a highly adaptable platform that does not require the intervention of the software company to be able to evolve. Customers or partners can answer specific needs very quickly.
To learn more about Stambia's ability to adapt, look at the following pages : the model driven approach and adaptative platform concept
Want to know more ?
Consult our resources



Did you not find what you wanted on this page?
Check out our other resources:
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration