
ETL vs ELT : Maximisez vos performances et réduisez vos coûts d'intégration
"Nous entrons dans un nouveau monde dans lequel les données peuvent être plus importantes que les logiciels." Tim O'Reilly
La transformation numérique et l'explosion du nombre de nouvelles applications a transformé la vision de la donnée au sein des systèmes d'information.
De nouveaux enjeux sont apparus :
- La diversité des sources de données ( Cloud, SaaS, IOT : internet des objets, internet )
- La démultiplication des volumes de données à traiter ( Big Data, Réseaux sociaux, Web )
- L'apparition de nouveaux types de données ( non structurée "texte, audio, vidéo, images" , non hiérarchique " NoSQL, Cluster")
Comment ingérer, nettoyer et transformer cette masse de données rapidement ?
Comment maitriser ses coûts d'intégration et préserver ses investissements d'infrastructure ?
Pourquoi les solutions ETL classiques ne répondent plus si bien aux besoins actuels ?
La solution Stambia Enterprise mise sur une approche différente dite de "délégation des transformations" des données, appelée aussi approche ELT.
Découvrez les différences fondamentales entre l'ancien monde ETL et la vision ELT.
Quels sont les bénéfices de l'approche ELT ?
ETL traditionnel confronté aux challenges de la transformation numérique
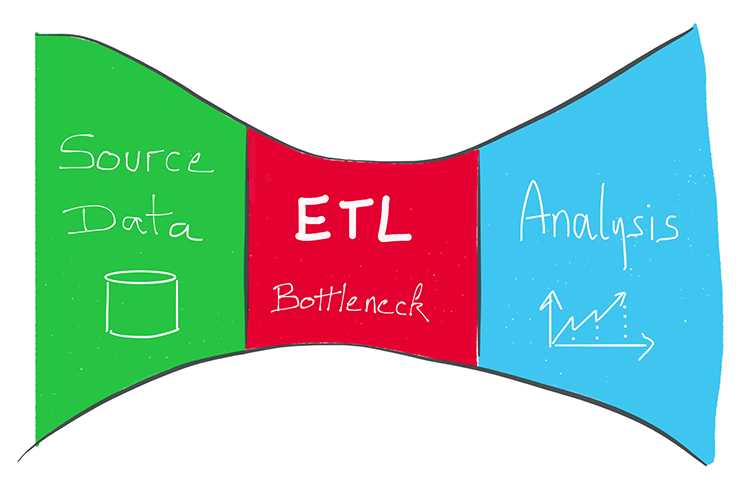
ETL : Qu'est-ce qu'un ETL ?
L'ETL ( Extraire, Transformer, Charger / "Load" ) est apparu dans les années 80.
Il s'agit de solutions logicielles permettant de répondre à des besoins de transformation de données entre des sources et des cibles : agréger et stocker des données de différents types, en provenance de multiples sources, vers une base de données cible.
Les outils qui s’inscrivent dans cette logique disposent en général d’un moteur (engine) dédié et propriétaire et sont installés sur des serveurs distincts.
Ils ont une vision centralisée des transformation des données. Tous les traitements de transformation se font par le biais du moteur ETL.
On peut citer par exemple Informatica, Cognos decisionStream, SSIS, DataStage, Talend, Genio ...
ETL : Quels sont les challenges des outils ETL traditionnels ?
"Les volumes de données explosent plus rapidement que jamais. D'ici 2020, environ 1,7 mégaoctets de nouvelles informations seront créées chaque seconde pour chaque être humain de la planète."
Avec une telle quantité de données générées chaque seconde, la nécessité d'extraire, transformer et charger ( stocker) ces données dans des systèmes tiers pour en tirer une information utile, est devenu un impératif pour chaque entreprise.
Cependant de par l'utilisation d'un moteur de transformation dédié, les outils traditionnels ETL du marché se confrontent aux limites suivantes pour gérer de gros volumes d'information. :
- Un effet goulot d'étranglement :
- Plus on développe des flux et plus la concentration sur le moteur de transformation ( engine) devient importante
- Cela peut-être pénalisant en terme de performance
- Cela sollicite de façon importante le trafic réseau (network)
- Ce type d'architecture peut se révéler coûteuse par :
- Le coût généralement lié à la puissance du moteur de transformation (facturation au processeur par exemple )
- Le coût à la ressource utilisée ( plus le volume de vos données sera importante et davantage de ressources devront être dédiées )
- La nécessité de localiser physiquement le moteur de transformation :
- Architecture Coud : nécessité de faire transiter les données par le moteur.
- Architecture Hadoop : même constat
30-40% : estimation du volume de données créées chaque année
Petite illustration des limites de l'approche ETL
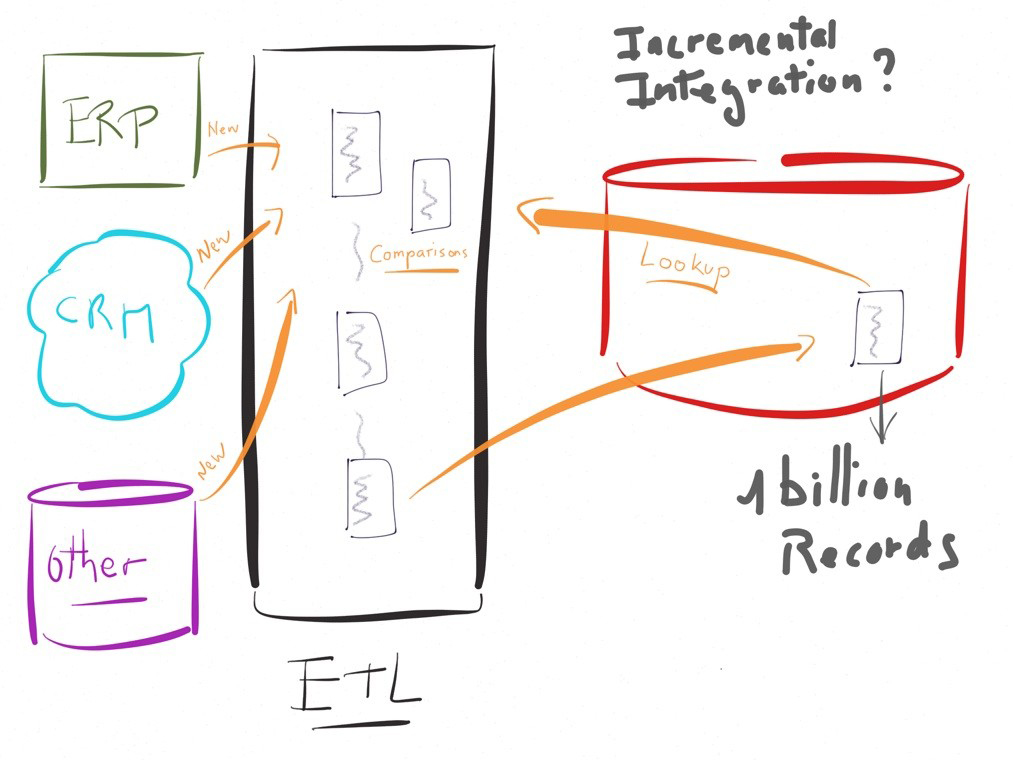
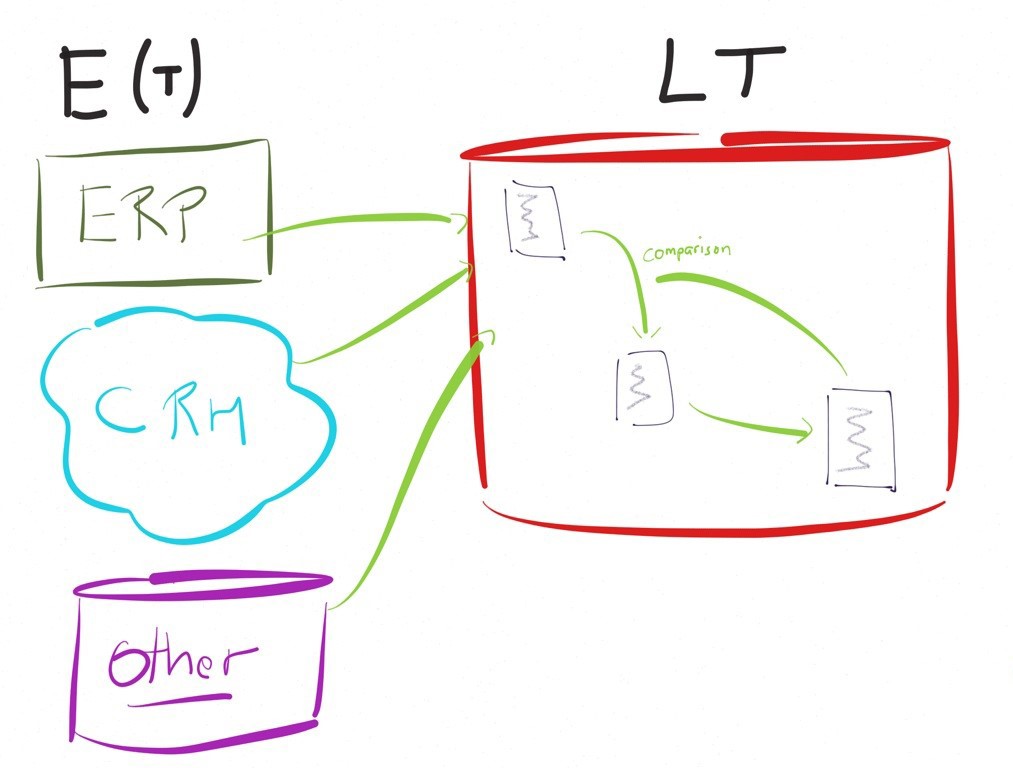
Pour nous convaincre de l’intérêt d’une approche E-LT prenons un exemple concret.
Imaginons qu’il faille alimenter un système décisionnel, disons une table dans une cible, contenant déjà des millions ou milliard d’enregistrements cumulés dans le temps.
L’alimentation en mode incrémental de cette cible à partir de quelques milliers de nouvelles lignes sur la source, c'est-à-dire en mettant à jour uniquement les modifications de la source depuis la dernière exécution, nécessitera une comparaison des nouvelles lignes avec les lignes existantes.
Dans une approche traditionnelle à base d’un moteur de transformation, l’exécution ressemblerait au schéma ci-contre, impliquant des fonctionnalités de lookup (ou équivalent) pour comparer les données.
Très rapidements, dans cet exemple, la performance sera un challenge important.
Dans un tel cas de figure les ETL traditionnels désavouent leur logique « moteur » en préconisant d’exécuter des instructions sur les bases de données plutôt que sur leur système.
L'approche par délégation des transformations, qu'est-ce que c'est ?
Définition ELT
L’approche ELT ( délégation des transformations ) consiste à tirer parti des systèmes d’information existants en faisant effectuer le travail de transformation aux technologies déjà en place ( technologies sous-jacente )
Les transformations sont réalisées par les bases de données ou les autres technologies manipulées (cluster hadoop, cluster cloud, cubes OLAP, systèmes d’exploitations, etc.).
Les extractions et intégrations de données peuvent être réalisées par le biais des outils natifs existants sur ces technologies.
Dans cette architecture la charge est répartie entre les différents systèmes : c'est une architecture non centralisée contrairement à l'approche ETL qui est centralisée.
Le moment où la transformation est effectuée et le lieu où elle s'exécute sont les deux éléments clés qui caractérisent une approche ELT.
Petite illustration des avantages d'une approche ELT
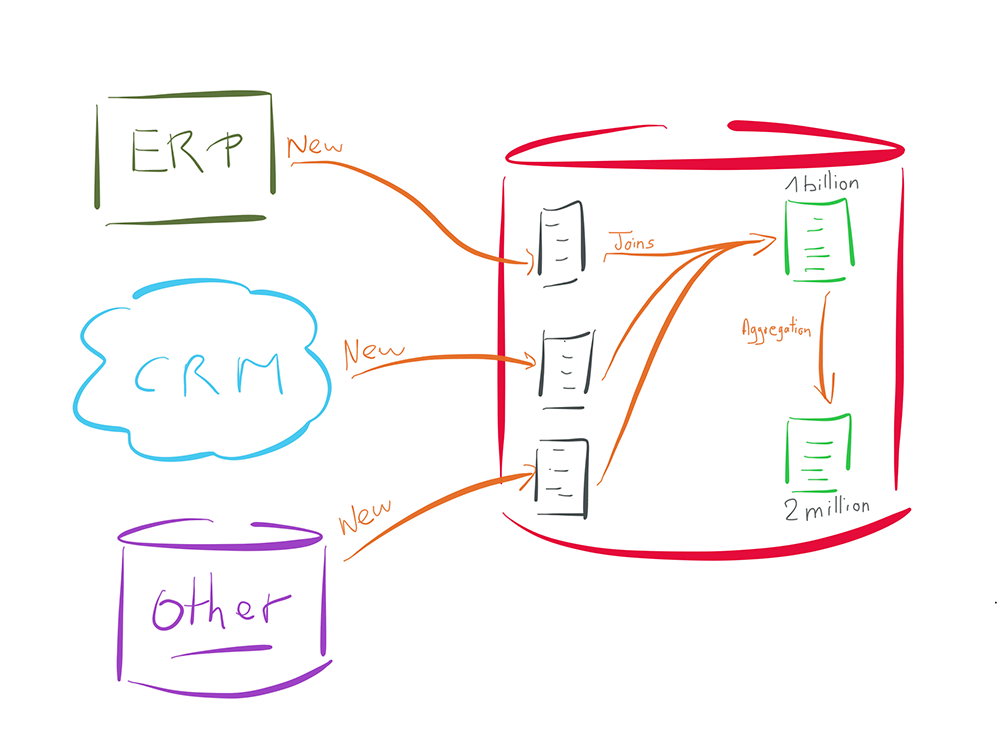
Pour illustrer reprenons l'exemple pris précement mais cette fois-ci avec une approche ELT.
Dans l'exemple précédent nous devions collecter quelques milliers de "nouveaux" enregistrements en source, puis les comparer à 1 milliard de données déjà enregistrées en cible.
L'approche ELT va consister à enregistrer les quelques milliers de données source dans un espace temporaire, du côté de la base cible (les trois tables en gris).
La comparaison va ensuite être effectuée directement au sein de la base de donnée cible, sans nécessiter d'opérations de look up ou autre opération qui serait coûteuse pour la base de données.
En effet, cette dernière va utiliser ses indexes ou autres mécanismes internes, qui sont optimisés pour ce type d'opération.
De même, une fois la donnée intégrée dans la table cible (la première table verte en haut du schéma), toute opération d'agrégation vers une autre table au sein de la même base de données (la deuxième table verte du schéma) ne nécessitera aucune action en dehors de la base de données (aucun moteur nécessaire en dehors de celui de la base de données).
Dans quels scénarios l'approche ELT est-elle meilleure ?
L'architecture ELT, meilleure approche pour les projets Cloud et les architectures hybrides ?
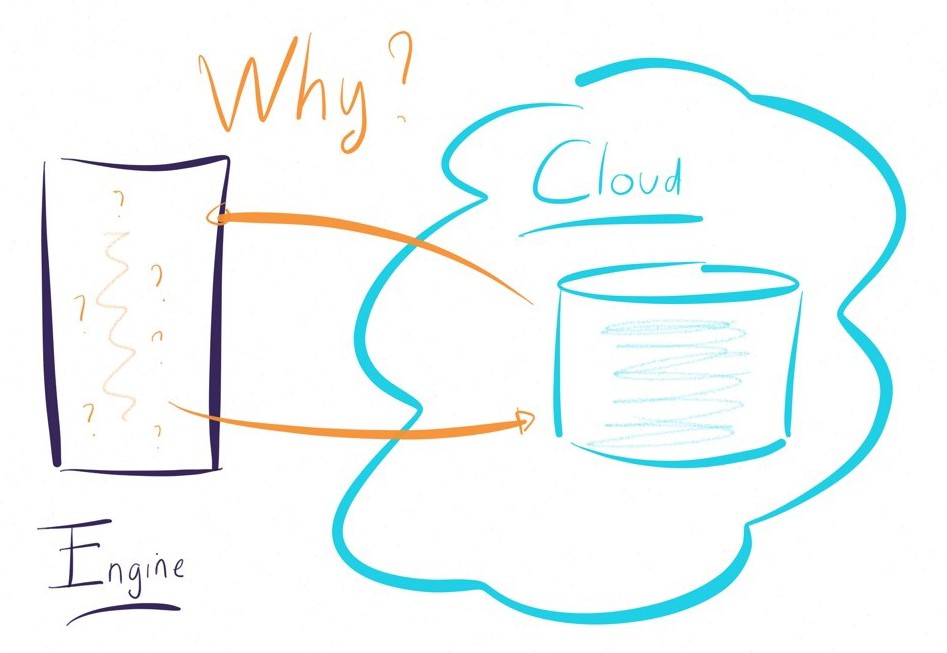
Comme précisé ci-dessus, une approche ETL nécessite l'usage d'un moteur de transformation. Que se passe-t-il avec des applicatifs hébergés dans le cloud ? Où positionne-t-on le moteur ?
L'usage du cloud se fait rarement à 100%. Cela implique, dans une approche ETL, la nécessité d'installer plusieurs moteurs (sur site et dans le cloud) pour gérer les différentes situations
La situation se complique dans des architectures multi-cloud (Amazon, Azure, Google..., Salesforce, Oracle...) : Doit-on installer plusieurs moteurs ETL ? Doit-on investir sur des ELT spécifiques au Cloud, au risque de perdre en capacité à rationaliser et gouverner les données ?
Au contraire le choix d'une approche ELT fonctionne dans tous les cas d'usage, car elle ne nécessite pas l'installation de moteurs propriétaires. Elle fera travailler les technologies sous jacentes et aura une empreinte très légère sur les systèmes.

L'avantage d'un ELT par rapport à un ETL pour vos projets Big Data
Les infrastructures à base Hadoop sont mises au point pour faire de la transformation de données sur des volumes importants et pour des cas complexes.
Pourquoi venir ajouter une couche intermédiaire ( moteur spécifique ) pour gérer ces données ?
L'approche ELT va permettre de déléguer l'ensemble des transformations et manipulation des données à ces puissantes plateformes que sont Hadoop, Spark et autres technologies Big Data ou NoSQL .
L'approche ELT, championne pour traiter de gros volumes de données ?
L'approche ELT évite de sortir la donnée des environnements pour la faire traiter par un moteur.
Prenons l'exemple qui consiste à agréger un ensemble de données au sein même d'une base de données.
Grâce à l'approche de délégation des transformations ELT, cela ne nécessitera pas de sortir la donnée et d'utiliser un moteur tiers.
La donnée restera dans son environnement, optimisant les performances et l'usage des ressources réseau.

Les bénéfices d'utiliser une solution ELT pour vos projets d'intégration de données
Résumé des avantages de l'ELT
L'approche ELT permet :
- De maximiser la performance
- Efficace : pas de technologie intermédiaire
- Rapide : dialogue en langage natif avec les acteurs mis en jeu
- De simplifier et de rationaliser l’architecture
- Non intrusif : aucun système supplémentaire à installer
- Distribué : la charge peut être lissée sur l’ensemble du système.
- D’optimiser l’utilisation des technologies déjà en place
- Rentabilité : la puissance disponible des systèmes existants est utilisée
- La connaissance et la maîtrise des systèmes par le client sont mutualisées
- Coût : réduire vos coûts d’infrastructure et capitaliser sur vos investissements
- D'être naturellement évolutif
- Scalabilité automatique : la puissance disponible des systèmes existants est utilisée. S'ils évoluent, l'ELT en tire partie.
- Déploiement rapide : l'ajout de sources ou de cibles ne nécessite pas l'ajout de moteurs. L'outil est opérationnel immédiatement.

Bénéfices de l'ELT Stambia
Une approche top down, le mapping universel pour développer
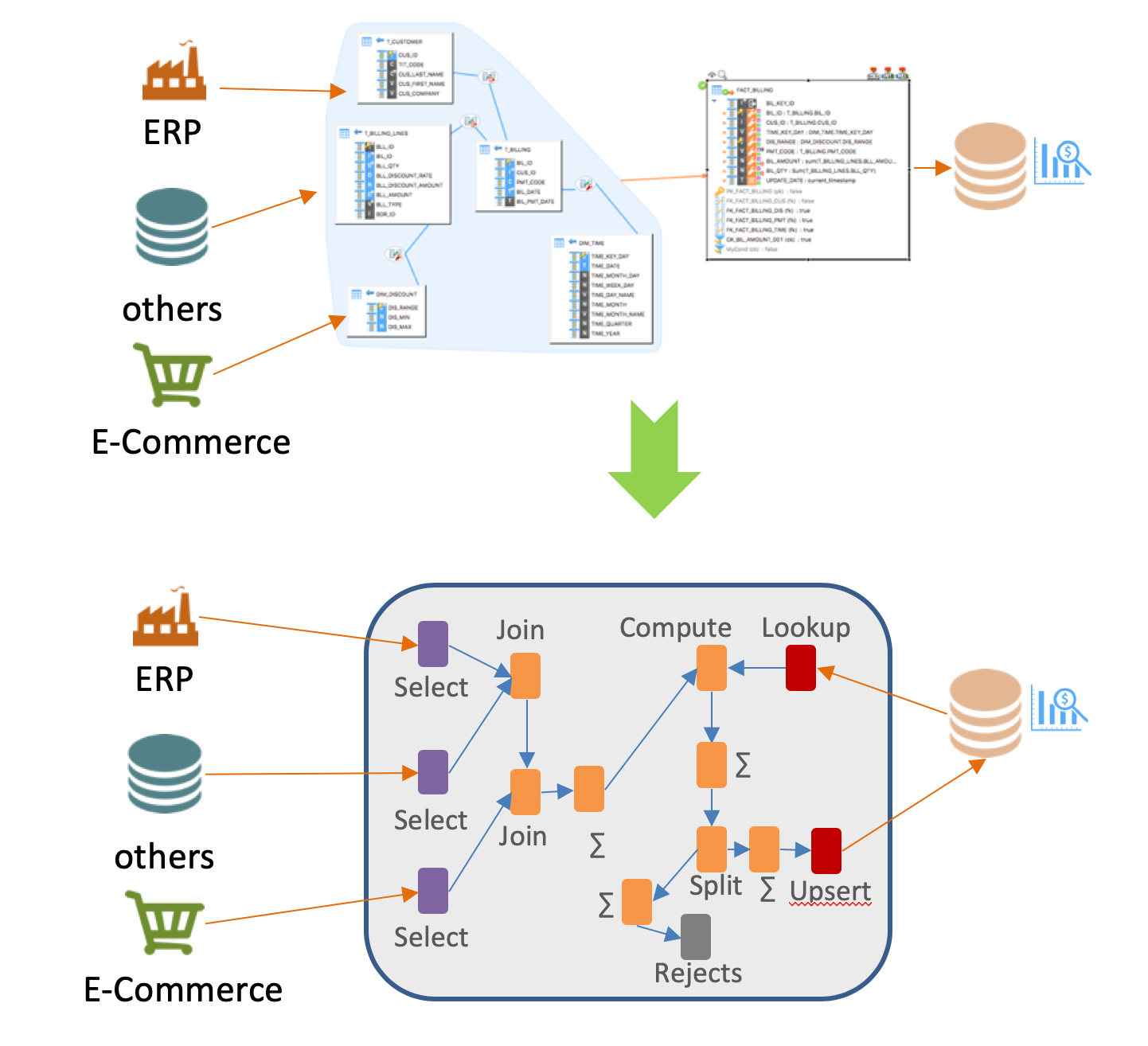
Un ELT n'a d'intétêt que s'il permet de simplifier le travail des développeurs, en faisant abstraction des technologies sous-jacentes pour donner une vision plus orientée "métiers" lors de développements.
Dans ce sens, la vision du mapping universel de Stambia permet de rendre accessible le mode ELT, sans nécessité de connaissances techniques avancées.
L'approche top down permet de développer en se focalisant sur les règles métiers, et de laisser Stambia générer la transformations sur les plate-formes adéquates. Cette génération automatique sera faite en utilisant les bonnes pratiques de chacune des technologies, ceci pour garantir les bons niveaux de performance.

Une solution entièrement personnalisable et autoadaptable
L'approche ELT ayant pour objectif d'optimiser au mieux les usages des technologies existantes (bases de données, serveurs, clusters...), il est important que l'ELT puisse s'adapter facilement et rapidement aux évolutions techniques.
Le monde informatique évoluant très rapidement, les nouveautés ne manquent pas d'arriver fréquement sur les plateformes technologies.
S'adapter rapidement n'est possible que si la plateforme ELT est prévue pour cela.
Stambia est une plateforme hautement adaptable qui ne nécessite pas l'intervention de l'éditeur pour évoluer. Les clients ou les partenaires peuvent très rapidement réagir à des besoins spécifiques.
Pour en savoir plus : consulter notre page sur l'approche par les modèles et celle sur le concept de plateforme adaptive
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources



Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration