
Los datos No SQL (XML, Json, Avro, Copybook Cobol…) con simplicidad
La gestión de archivos de datos es una problemática actual, particularmente en la época del Big Data y del NoSQL.
Cada vez más datos son almacenados en estructuras de archivos planos o archivos jerárquicos (Json, XML,…) de los cuales algunos son muy específicos del área de Big Data, como Avro. Estas estructuras jerárquicas están ya sea disponibles directamente en los sistemas de archivos (Windows, Linux, Hdfs, Amazon, Azure…) o encapsulados en la tecnología de un tercero (Elastic Search, Mongo DB, Big Query, Snowflake, Teradata…).
Descubra las funcionalidades de Stambia que permiten acelerar los proyectos que requieren el uso de archivos y estructuras jerárquicas.

XML, JSON, Avro… ¿Por qué a veces es complicado?
Soluciones ETL tradicionales adaptadas a los formatos simples
Las soluciones tradicionales de integración de datos han sido frecuentemente diseñadas para datos de formato tabular.
La gestión de datos jerárquicos es realizable pero costosa en términos de tiempo de desarrollo y a veces poco eficaz en términos de rendimiento.
No es raro perder mucho tiempo y energía en proyectos que manipulan simples datos jerárquicos (archivos provenientes de grandes sistemas, archivos con Copybook Cobol, datos NoSQL como JSON o Avro, datos provenientes de servicios web en XML, etc.).

Problemáticas de volumen de datos

Las cosas se compliquen frecuentemente cuando el volumen de datos aumenta.
Dos casos en concreto pueden presentarse:
- Cada archivo es de un tamaño importante y requiere aumentar de manera importante la potencia de la máquina, particualrmente la memoria, con el fin de que el archivo pueda ser leído sin fallas del ELT.
- El número de archivos es importante y los mecanismos de paralelización no son eficaces. Debido a esto, el tiempo necesario para el procesamiento de un lote de archivos se hace prohibitivo o penalizador para los equipos de procesamiento.
XML, JSON... Formatos de datos no siempre fácil de entender
En fin, no todo el mundo es un especialista de las tecnologías jerárquicas, particularmente los Web Services o los formatos muy específicos como Avro o Json.
La manipulación de tales estructuras con las soluciones tradicionales u Open Source puede requerir competencias técnicas nada insignificantes y hacer más lento el tiempo de reacción con respecto a una solicitud del negocio.
Cada pequeña particularidad (un tipo de datos no comprendido o un formato específico del archivo) puede hacer perder mucho tiempo.

¿Cómo Stambia ETL gestiona las estructuras jerárquicas?
1. Simplificar el uso de los datos jerárquicos con Stambia ETL
La Representación de los datos por los metadatos
La gestión de los archivos en Stambia es simple.
Numerosos asistentes permiten ayudar al usuario en la recuperación de los metadatos. Están adaptados a cada tecnología, tomando en cuenta cada una de las especificidades.
Cuando las tecnologías lo permiten, Stambia propondrá utilizar estándares de ingeniería inversa específicos (XDS, DTD, WSDL, etc.). Cuando éste no es el caso (formato libre), el asistente propondrá utilizar datos de ejemplo con el fin de recolectar el máximo de información.
En todo momento, el usuario podrá corregir y agregar sus propias informaciones con el fin de tener una descripción de los objetos que sea la más fiel a los datos que tendrá que procesar.
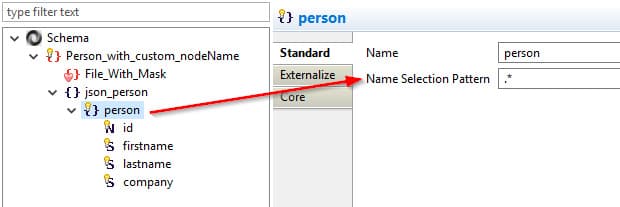
La exploración de los datos jerárquicos
La exploración de los datos jerárquicos
El Designer Stambia permite leer directamente los datos jerárquicos de tipo JSON o Avro con un editor especializado.
Cuando se trata de archivos jerárquicos de otro tipo, el conector integrado, el cual es un piloto JDBC, puede leer o escribir archivos de tamaño delimitado o fijo y puede gestionar los eventos dentro de una misma línea (longitud variable del mismo tipo de línea).
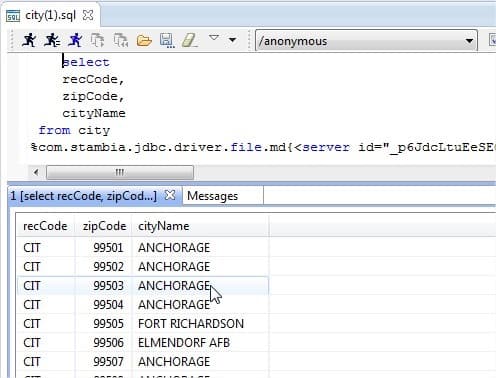
Una vez elaborada la descripción del archivo, es posible efectuar simples comandos SQL para leer el archivo como si estuviese compuesto de varias tablas (ver la imagen).
2. Leer y escribir el dato jerárquico de manera eficaz
Lectura / carga de datos jerárquicos con Stambia
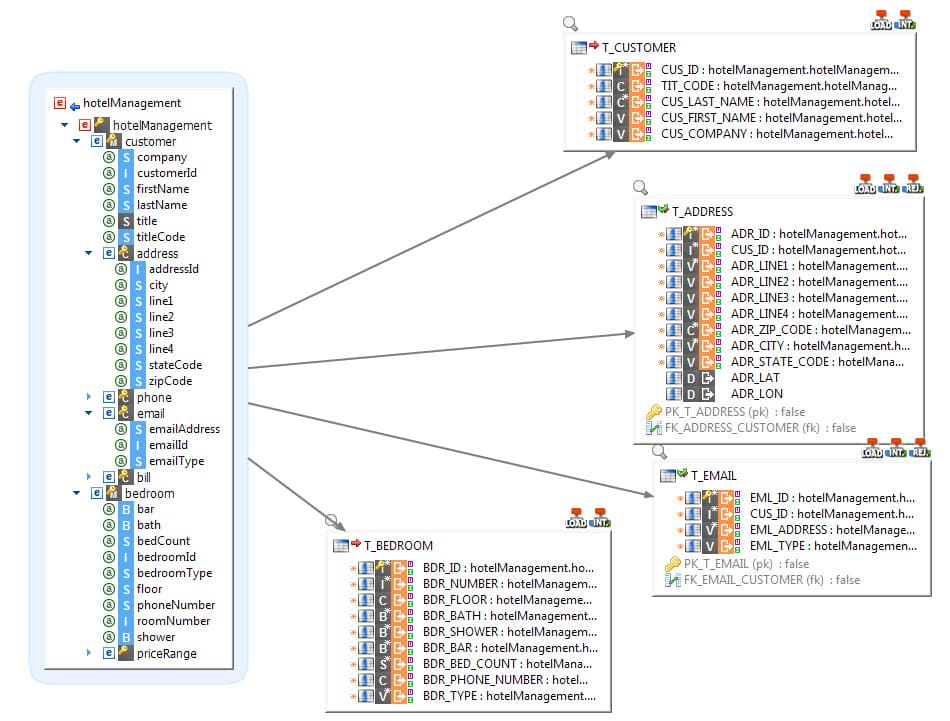
El mapping universal de Stambia proporciona la mejor manera de leer archivos complejos con el fin de cargas varios destinos con un nivel de rendimiento extremadamente elevado.
En efecto, el enfoque "multi-destinos" del mapeo se mantiene simple, permitiendo igualmente cargar múltiples destinos a partir de un único archivo. Los archivos serán cargados una sola vez, pero los datos serán enviados al mismo tiempo (o de acuerdo a la secuencia solicitada) hacia varios destinos.
Esto proporciona un nivel elevado de rendimiento para leer, utilizar y transformar datos jerárquicos fuente.
Este enfoque también está orientados a los datos (data-centric). Permite al usuario concentrarse en el enlace entre sus datos y no en el proceso técnico que es necesario para la realización del mapeo.
Escritura de datos jerárquicos con Stambia
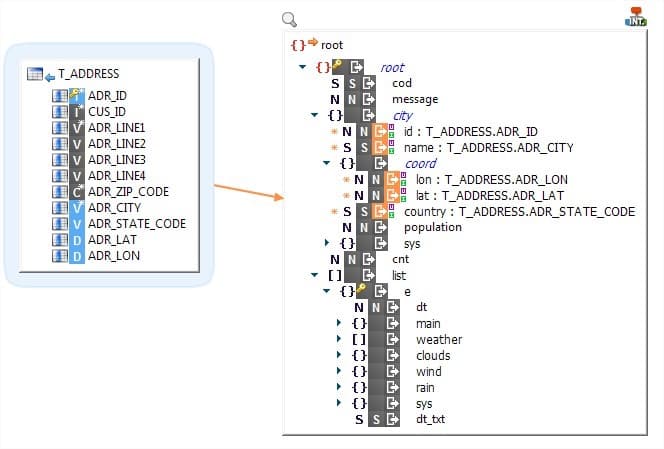
Stambia puede integrar los datos en un archivo o estructura jerárquica con un sólo mapeo y esto sin importar la complejidad de la estructura abordada.
En el ejemplo mostrado, el destino del mapeo es un archivo XML, compuesto de varias jerarquías.
Sin dejar de ser legible, un sólo mapeo permitirá producir un archivo jerárquico único, que puede contener jerarquías muy profundas, o también contener múltiples ocurrencias de los mismos elementos, o incluso jerarquías yuxtapuestas.
Como referido precedentemente para la lectura de datos, este enfoque es orientado a los datos (data-centric). Permite al usuario concentrarse en el enlace entre sus datos y no en el proceso técnico que es necesario para la realización del mapeo.
Este enfoque es muy útil igualmente al usar Web Services o API que utilizan este tipo de datos jerárquicos para las entradas (inputs) y salidas (outputs).
3. Automatizar e industrializar con Stambia ETL
Industrializar la lectura o la escritura de archivos en repositorios
La manipulación de archivos requiere a veces la repetición de las mismas operaciones en varios archivos idénticos.
Por ejemplo, leer varios archivos idénticos en la fuente y repetir: varios comandos o lotes de comandos para integrarlos en un ERP o CRM. O también generar varios archivos a partir de un mismo conjunto de datos fuente: generar un archivo por ciudad o por proveedor.
Estas operaciones pueden revelarse complejas con las soluciones tradicionales.
Stambia propone numerosas funcionalidades que automatizan estos procesos, particularmente la posibilidad de gestionar en un mapeo el nivel repositorio o archivo con el fin de automatizar (sin proceso técnico adicional) la lectura o escritura en lote de estructuras jerárquicas.
Este enfoque permite mantener una visión orientada al negocio (data-centric) de los desarrollos, y sobre todo garantizar rendimientos óptimos a la hora del procesamiento de lotes de archivos importantes.
Replicar datos jerárquicos (XML, JSON, Avro…) automáticamente

La integración de archivos fuente en un destino puede también automatizarse utilizando el componente de replicación.
Este componente permite recorrer un repositorio e integrar masivamente archivos en una base de datos relacional o cualquier otro destino estructurado.
En este caso, no hay ni mapeo ni desarrollo. El replicador es capaz de crear una estructura relacional (u otra) a partir de una estructura jerárquica de archivo y de completar la base de datos con archivos que fueron encontrados en el directorio.
Este tipo de componente puede incorporar mecanismos de integración incremental (con cálculo de diferencias) para integrar de manera coherente y sin duplicaciones de datos en un destino.
Este componente permite recorrer un repositorio e integrar masivamente archivos en una base de datos relacional o cualquier otro destino estructurado.
En este caso, no hay ni mapeo ni desarrollo. El replicador es capaz de crear una estructura
Especificaciones técnicas
| Especificaciones | Descripción |
|---|---|
|
Arquitectura simple y ágil |
|
|
Protocolp |
HDFS, GCS, Azure Cloud HTTP REST / SOAP |
|
Formato de datos |
XML, JSON, AVRO, y todo formato específico ASCII, EBCDIC, Montos comprimidos, Apache Parquet , ... |
| Conectividad |
Puede extraer los datos de:
Para saber más, consulte nuestra documentación técnica |
| Conectividad técnica |
|
|
Características estándar |
|
| Características avanzadas |
|
| Requisitos técnicos |
|
| Despliegue en la Nube | Image Docker disponible para los motores de ejecución (Runtime) y la consola de ejecución (Production Analytics) |
| Estándares soportados |
|
| Lenguaje de Scripting | Jython, Groovy, Rhino (Javascript), ... |
| Gestor de versionamiento | Cualquier plugin soportado por Eclipse : SVN, CVS, Git, ... |
¿Desea saber más?
Consulte nuestros diferentes recursos


¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos

La gestión de formatos de datos jerárquicos como XML, JSON, SAP IDOCS o servicios web puede ser muy compleja.
¿Qué desarrollador no se ha quejado nunca de la dificultad y la pérdida de tiempo inducido por el procesamiento de este tipo de datos?
Esto es comprensible ya que las soluciones tradicionales de integración de datos, diseñadas para formatos de datos más simples como tablas y archivos planos, resultan en una productividad y un rendimiento pobre al lidiar con este tipo de estructura. ...
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration