
Le composant Stambia pour Google BigQuery
Google BigQuery est une soluction d'entrepôt de données d'entreprise (Data Warehouse) qui ne requiert pas de serveur (serverless), hautement scalable qui ne nécessite pas de gestion d'infrastructure et supporte les analyses sur des très grandes volumétrie de données à l'échelle Peta-byte.
Le composant Stambia pour Big Query permet de manière simple et agile d'intégrer et de manipuler les données dans Big Query. Il exploite nativement les caractéristiques de BigQuery pour :
- La gestion du stockage en colonne
- Le traitement des exécutions massivement parallèles
- L'optimisation automatiquement des performances
Différents cas d'usages du composant Google BigQuery
Réduire le time to market
L'objectif de mettre ses données dans Google BigQuery c'est de permettre des analyses plus rapides sur des plus grandes volumétries de données.
Rendre les données accessibles pour les analystes de données et les Data Scientist est devenu primordiale. Dès lors, la clé pour les ingénieurs de données est de mettre à disposition les données le plus rapidement possible. Les solutions traditionnelles d'intégration de données sont souvent complexe à installer, configurer, développer des flux et à maintenir.
La solution d'intégration de données idéale doit fonctionner en synergie avec BigQuery de manière légère et facile d'accès.

Migrer vos données On-Premise vers Google Big Query
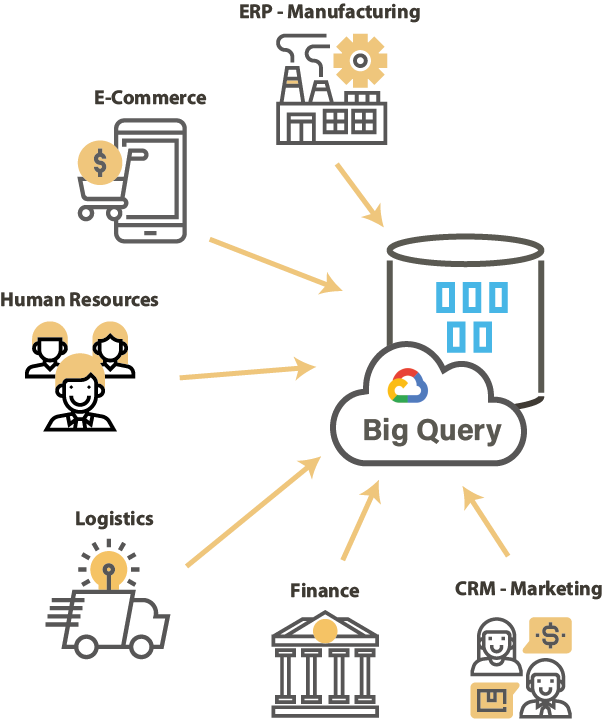
La migration des données d'un système OnPremise vers un système Cloud est un des enjeux majeurs dans la réussite globale de l'adoption des systèmes Cloud. La migration doit contribuer non seulement à moderniser l'architecture mais aussi à améliorer les données.
Pour ce faire, les experts en migration de données ont besoins d'un outillage flexible et paramétrable afin de pouvoir traiter rapidement les différents cas de migration et d'amélioration. En effet, il est fréquent de rencontrer des complications lors des différentes phases d'un projet de migration. Disposer d'une solution d'intégration qui facilite la migration est un plus dans la réussite de ce type de projet.
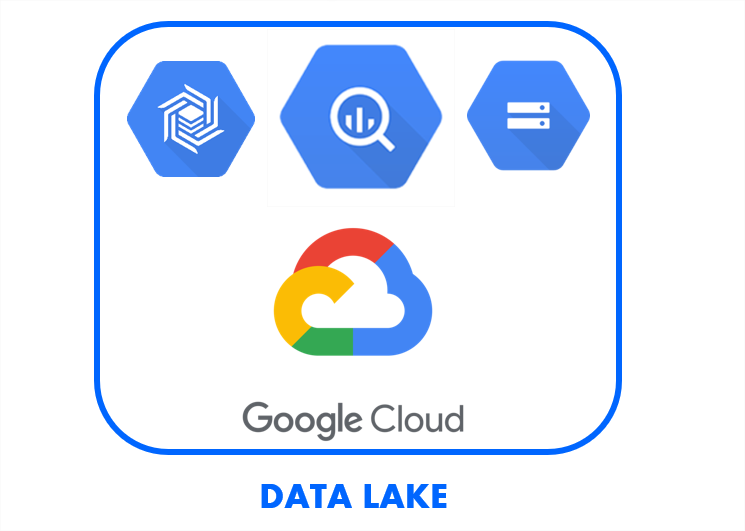
Construire un Datalake
La plateforme Cloud de Google : Google Cloud Platform ou GCP est une solution particulièrement adaptée pour construire un lac de données ou Data Lake. BigQuery y jouera un rôle clé. Les données brutes peuvent être injectées dans le stockage Cloud de Google : Cloud Storage. Ensuite, celles-ci peuvent être chargées dans BigQuery pour y constituer une couche de données ou mises à disposition des Data scientist afin de construire leurs modèles pour le Machine Learning (ML).
Dans un projet de Data Lake, il est important de pouvoir traiter différents types de jeux de données issues de technologies hétérogènes, gérer les différents formats. La capacité à gérer ces différents contraintes sera la clé de réussite du projet. L'objectif est de réduire le recours à différentes solutions d'intégration pour couvrir chaque besoin.
Maîtriser les coûts et réduire le TCO

L'un des principaux avantages dans l'utilisation de BigQuery est de reprendre le contrôle sur les coûts de possession (TCO). Les composants impliqués dans un projet Cloud de Google doivent suivre cette même philosophie.
Néanmoins, les solutions d'intégration de données proposent souvent des coûts directs (clair) et indirects (cachés) qui rendent difficile la compréhension globale des coûts impliqués.
La solution d'intégration de données doit avoir des coûts de possessions clair et fournir une trajectoire lisible pour aider à définir des objectifs clairs au niveau budgétaire.
Caractéristiques du composant Stambia pour Google Big Query
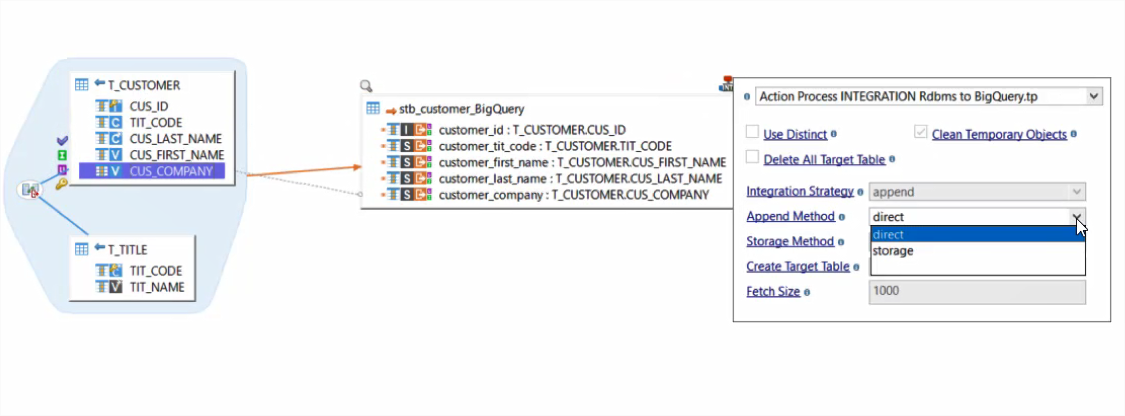
Le composant Stambia pour BigQuery permet de se connecter rapidement au jeux de données et réaliser des mappings de données visuels via Drag'n'Drop. L'utilisateur dispose de différentes méthodes de chargement :
- Chargement direct
- Chargement par le stockage Cloud Storage
- Au fil de l'eau par Streaming
Grâce aux templates Stambia pour Google BigQuery, l'utilisateur dispose d'une variété pour l'intégration, ce qui simplifie le design et permet de gagner du temps sur les développements.
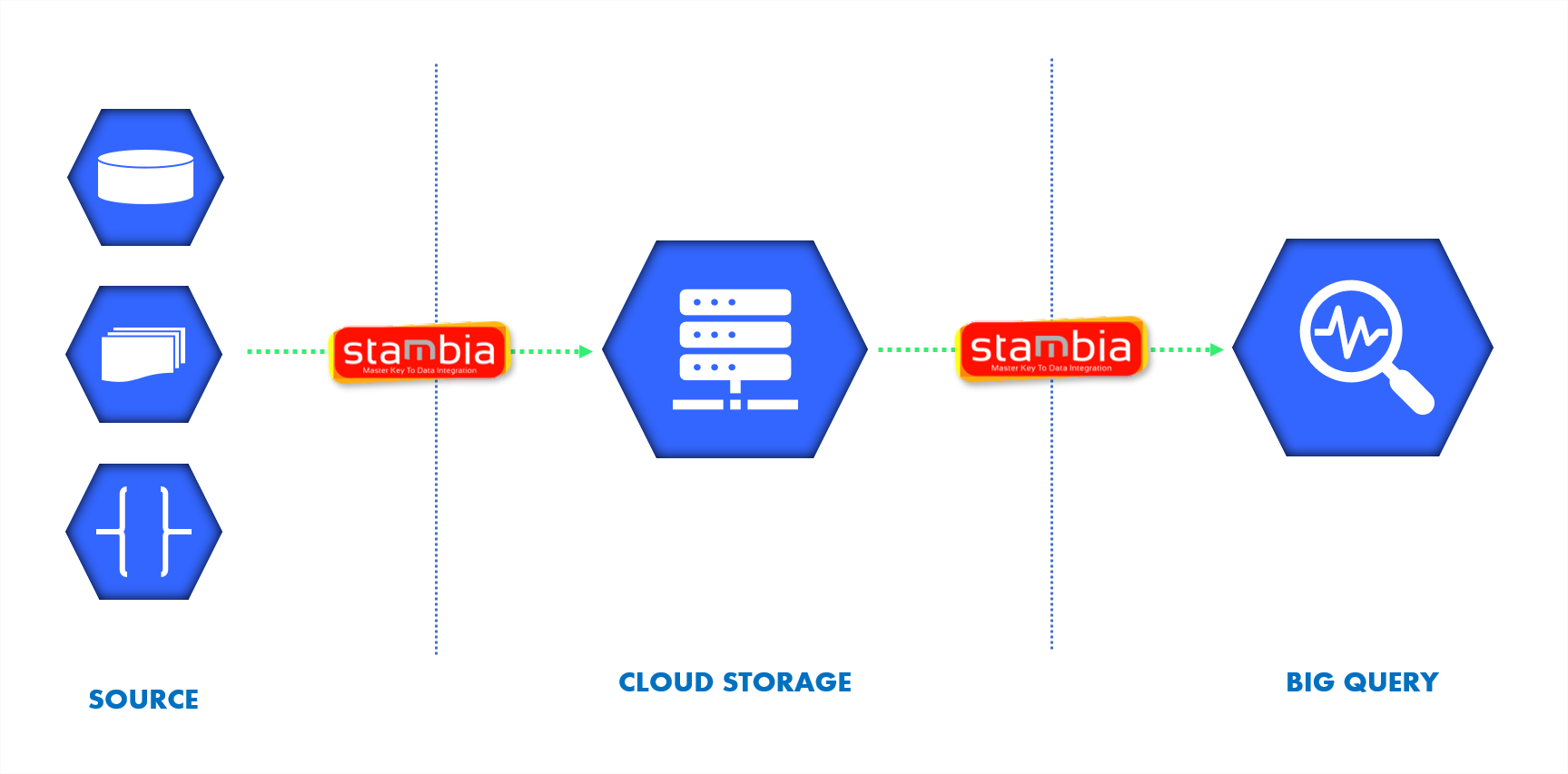
Accélérer l'intégration de données dans Google BigQuery avec Stambia
Le composant BigQuery pour Stambia a été conçu pour simplifier l'intégration avec une interface graphique conviviale et des modèles conçus pour réduire l'écriture manuelle de code et de scripts. Stambia propose des templates spécifiquement conçus pour BigQuery. L'utilisateur se concentre alors sur le paramétrage visuel des ses pipelines d'intégration par un simple Drag'n'Drop.
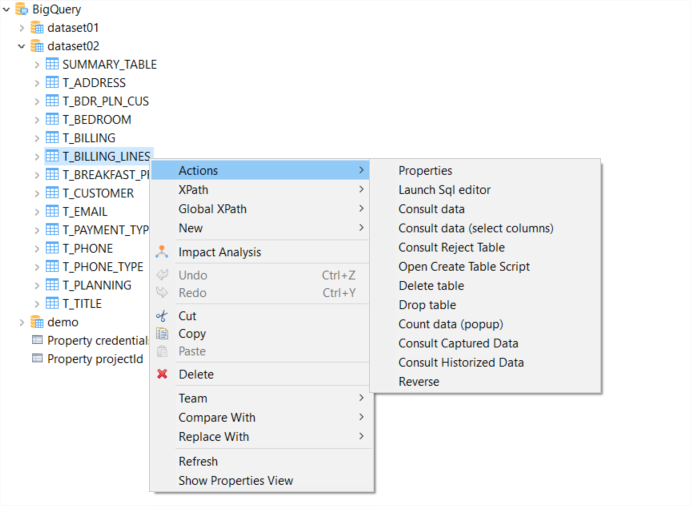
De plus le connecteur pour BigQuery a été conçu spécifiquement exploiter les capacités natives autour du SQL de BigQuery. Ceci grâce aux fonctionnalités intégrées dans Stambia pour traiter le SQL. Les développeurs travaillent ainsi d'une manière beaucoup plus simple avec BigQuery. Depuis les métadonnées, il est possible de consulter les données, lancer des requêtes, etc.
Simplifier la migration de données de vos systèmes Legacy OnPremise vers Google Big Query
Pour les projets de migration de données, il est important de pouvoir traiter de manière simple et rapide les aspects techniques. En effet, il est fréquent de rencontrer différentes problématiques au fil de la migration. Stambia propose des solutions personnalisées qui permettent d'apporter la flexibiltié nécessaire.
Par ailleurs, Stambia offre un template spécifique de réplication des données pour BigQuery. Ce "replicator" permet de répliquer les données en seulement 4 étapes. Le template fournit par Stambia est complétement paramétrable pour assurer les besoins spécifiques de migration.
De plus, de nouveaux templates peuvent être créés et mis à disposition pour des scénarios spécifiques de migration de façon très rapide. L'équipe projet peut ainsi atteindre les différents jalons en toute confiance et sans obstacles.
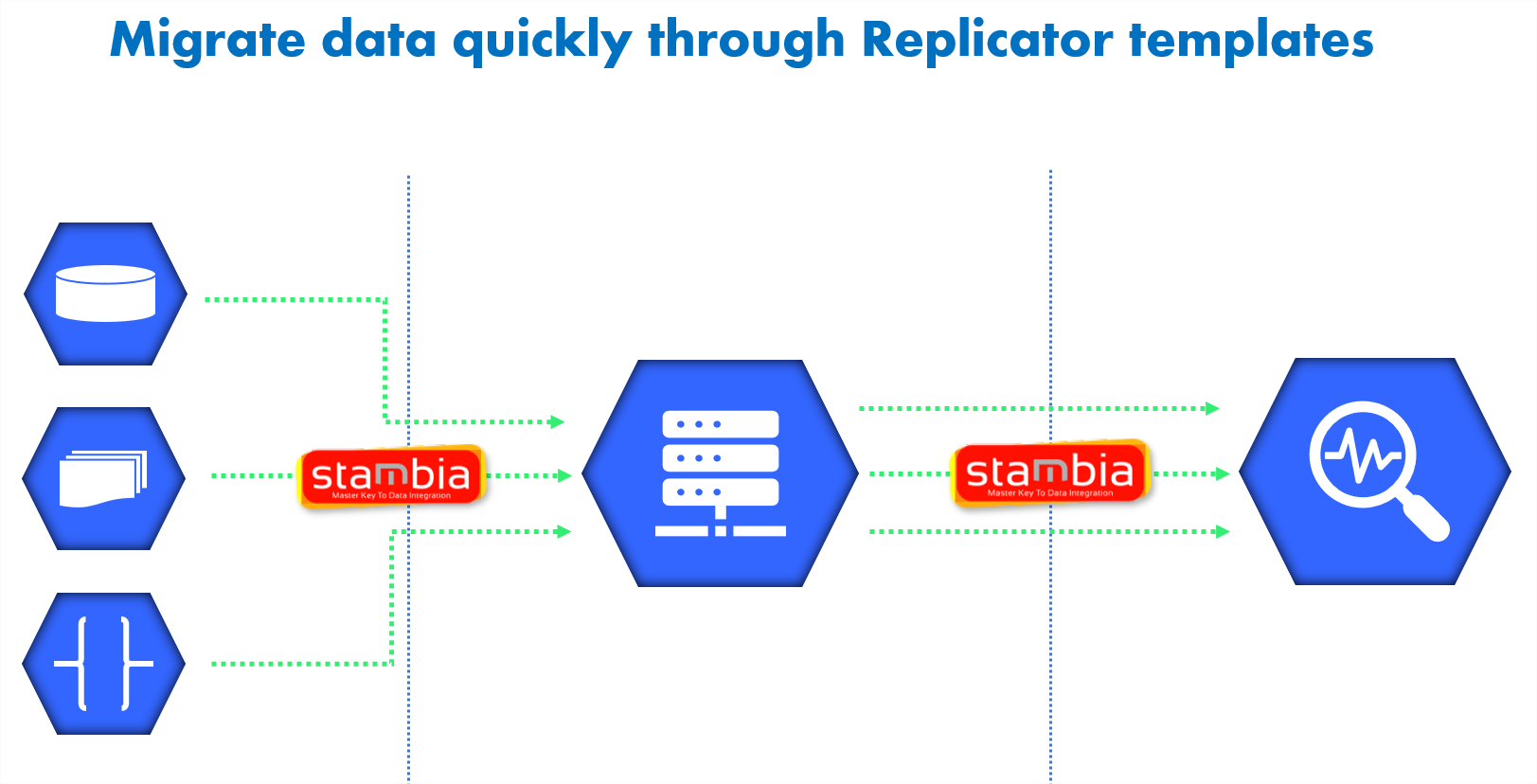
Pour en savoir plus sur la migration de données, découvrez notre vidéo sur notre outil de réplication de données "Replicator tool" :
Utiliser une solution d'intégration agnostique de l'architecture
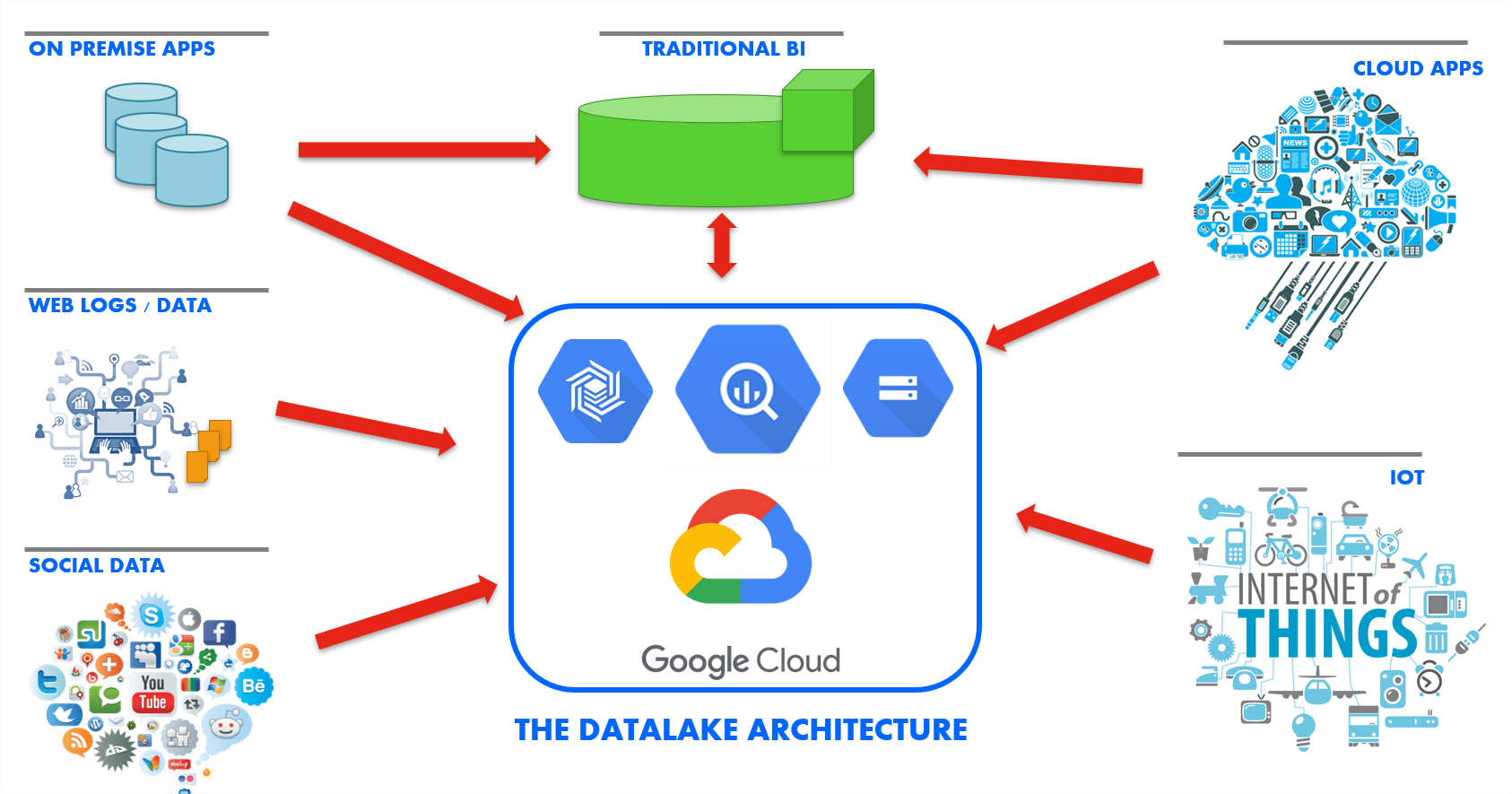
La solution unifiée d'intégration de données Stambia peut fonctionner avec différentes types d'architectures, de plateforme et de technologies. Avec la même solution, il est possible de démarrer simplement un projet d'intégration de données dans BigQuery pour ensuite évoluer dans la mise en place d'un Data Lake dans Google Cloud Platform.
Stambia dispose d'une connectivité à toutes sortes de base de données mais aussi à toutes les technologies habituelles ou modernes. Stambia permet de travailler de la manière avec des données structurées ou non structurées. Cela confère aux équipes IT un avantage pour faire évoluer librement et simplement l'architecture du système d'information.
Réaliser des analyses grâce à l'interface graphipe et le Drag and Drop
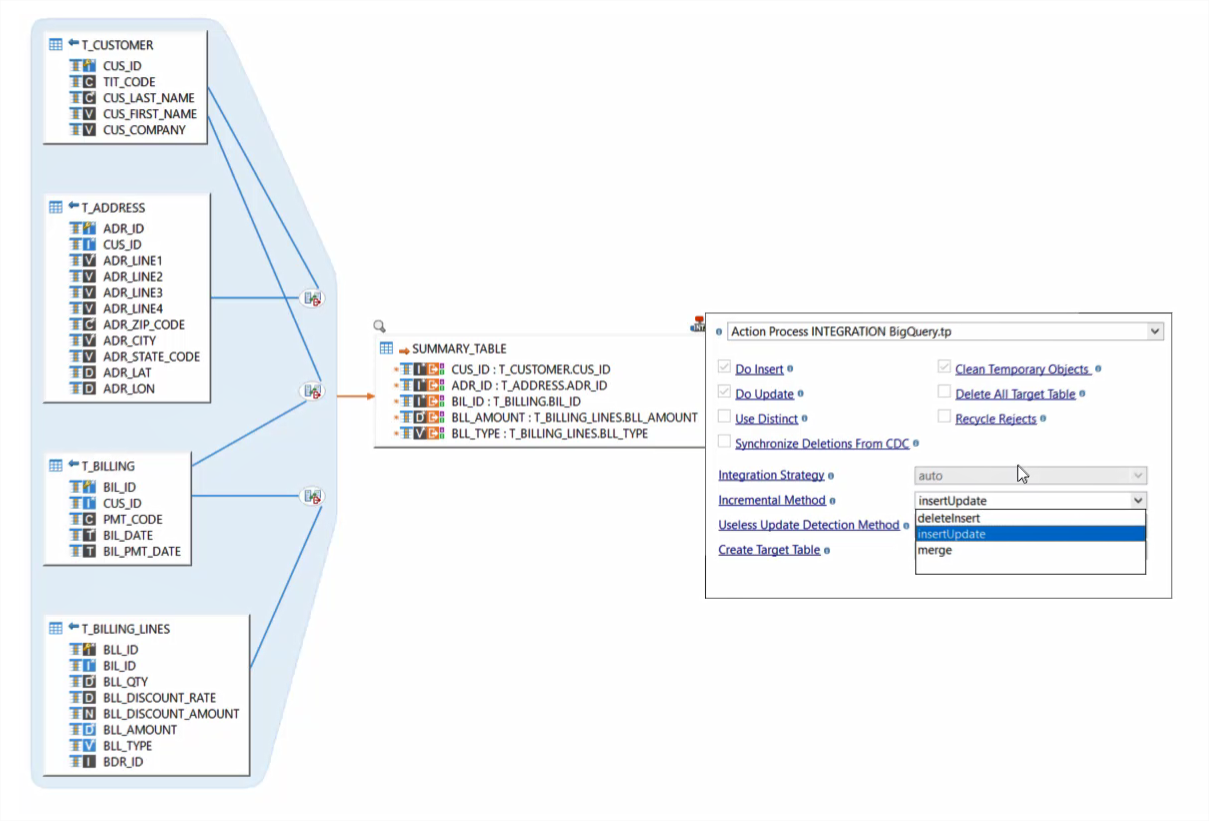
BigQuery est réputé pour offrir des analyses rapides sur des larges volumétries de données. Grâce à Stambia, après avoir injecté les données dans BigQuery, il est possible de réaliser très rapidement des requêtes de manière visuelle en utilisant le mapping et les Drag'n'Drop de métadonnées. Tout cela au sein de la même interface. Les bénéfices sont nombreux notamment celui de pouvoir voir visuellement la requête sans à avoir à écrire du code, de pouvoir changer rapidement en ajoutant une nouvelle jointure ou un filtre.
Par exemple : en cas d'extraction de données d'un système legacy, les tables peuvent avoir une intégrité référentielle. Quand ces tables sont mises en stagging dans BigQuery, il est possible de créer rapidement un mapping pour joindre les éléments, créer une vue dénormalisée des données et la stocker dans une autre table de BigQuery.
Une confiance dans les coûts de possession
Stambia offre une lecture simple et claire de son offre tarifaire. Sans tenir compte de paramètres complexes à gérer comme le nombre de sources, la volumétrie de données manipulées, le nombre de pipeline d'intégration, etc.
Grâce à un modèle de prix simple, l'équipe Stambia travaille à vos côtés afin de vous aider à bien calibrer et maîtriser les différentes phases de votre projet. Nos valeurs sont les fondements de votre réussite : apporter de la valeur et respecter nos engagements.

Spécifications et pré-requis techniques
| Spécifications | Description |
|---|---|
|
Protocole |
JDBC, HTTP |
|
Données structurées et semi-structurées |
XML, JSON, Avro (à venir) |
|
Stockage |
Lorsque vous intégrez des données dans Google BigQuery en utilisant un stockage Cloud, vous avez le choix :
|
| Connectivity |
Vous pouvez extraire les données de :
Pour plus d'informations, consulter notre documentation technique
|
|
Caractéristiques standard |
|
| Caractéristiques avancées | Le compostant Stambia pour Google BigQuery utilise par défaut les requêtes en mode Standard SQL. All statements supported by Google BigQuery's Standard SQL can therefore be used seamlessly without any particular configuration. Data can be sent to Google BigQuery with the following methods:
|
| Version du Designer Stambia | À partir Stambia Designer s18.3.8 |
| Version du Runtime Stambia | À partir Stambia Runtime s17.4.7 |
| Notes complémentaires |
|
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources



Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :

Découvrez notre webinar : Google BigQuery
Webinar : Accélérez l'intégration de données vers Google BigQuery
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration