
Le composant Stambia pour Snowflake
Snowflake est un entrepôt de données (Data Warehouse) qui fonctionne en mode service opéré depuis le cloud. En comparaison avec les systèmes de Data Warehouse traditionnels, Snowflake est plus rapide, plus flexible et plus simple à utiliser.
Le composant Stambia pour Snowflake est construit avec la même philosophie : fournir une intégration de données rapide, flexible et simple à utiliser notamment avec Snowflake. L'approche unifiée de Stambia permet aux utilisateurs de se familiariser rapidement avec les tâches d'intégration et ainsi de réduire significativement le Time to market.
Différents cas d'usage du composant Stambia pour Snowflake
Simplicité et Agilité
Snowflake est choisi comme solution d'entrepôt de données (Data Warehouse) pour sa simplicité d'utilisation, sa capacité à monter en charge et ses facilités pour interroger rapidement les données.
Voici les points clés :
- Pas de matériel (Hardware) à choisir, installer ou configurer
- Pas de logiciel à installer ou configurer
- Maintenance et gestion opérée directement par Snowflake
Ces éléments permettent d'apporter simplicité et agilité dans la mise en œuvre d'un entrepôt de données nouvelle génération Snowflake. En parallèle, il est important de disposer d'une couche d'intégration (de données) qui soit aussi simple et agile.

Migrer vos données On-Premise vers Snowflake
La première phase - à ne pas négliger - pour démarrer un projet Snowflake consiste à déplacer les données On-Premise existantes vers un nouvel entrepôt de données Snowflake situé dans le Cloud.
Un projet de migration de données nécessite de mettre en place une organisation et une planification. La volumétrie contenue dans un entrepôt de données est souvent très importante. Les données ne peuvent être migrées en une seule fois. Il faut donc définir un plan de migration et des opérations à effectuer (filtrage des données, réconciliation de données, etc.).
D'après le Gartner "Encore en 2019, plus de 50% des projets de migration de données dépasseront le budget et les délais et/ou nuiront à l'activité, en raison d'une stratégie et d'une exécution défaillantes"
Une migration des données nécessite également d'automatiser et de simplifier de nombreuses actions. Des éléments clés pour apporter l'agilité nécessaire afin de réussir cette première phase indispensable.
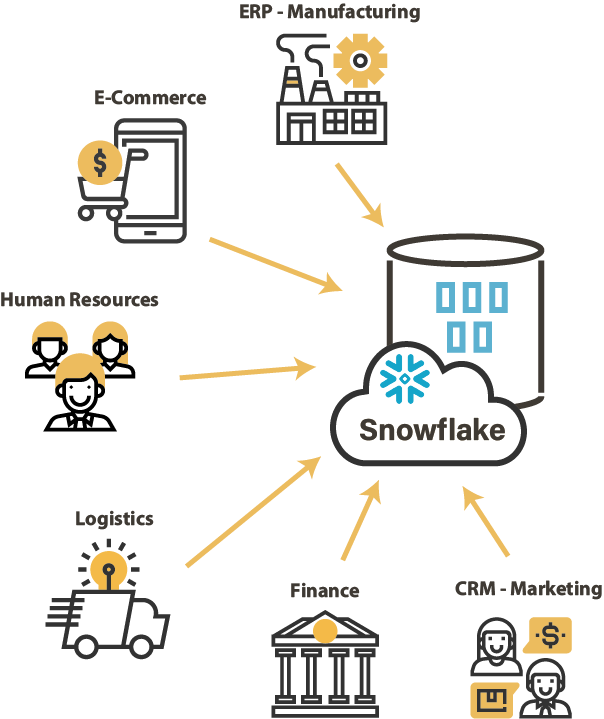
Intégrer toutes vos données
Comme tout entrepôt de données, Snowflake doit être alimenté par des données issues des différents systèmes eux-mêmes basés sur des technologies hétérogènes. Il est nécessaire de disposer d'une couche d'intégration de données qui soit capable d'importer ces données, tout en conservant une cohérence et éviter une multiplication des outils techniques d'intégration.
Dans le cadre d’une stratégie de données à l’échelle de l’entreprise, avec des cycles de changement d’architecture qui s’accélèrent, la couche d'intégration de données sera la clé pour déverrouiller les données de l'entreprise et prendre des décisions rapides et réduire les délais de mise sur le marché (Time to market).
Performance et Scalabilité

Snowflake utilise la technologie des traitements massivement parallèle (MPP) : il alloue automatiquement les noeuds de calcul en fonction de la puissance nécessaire pour chaque "entrepôt virtuel" où seront traités les requêtes. Pour cela, Snowflake repose sur un fournisseur de Cloud Computing (Amazon AWS ou Microsoft Azure). Ainsi, Snowflake assure performance et scalabilité avec des montées en charge gérées nativement et de manière transparente pour les utilisateurs de cette solution de Data Warehouse en mode SAAS.
Dans ce contexte, la couche d'intégration de données doit savoir tirer partie de ce type d'architecture. Pour cela, un outil basé nativement sur le mode ELT constitue la solution la plus efficace et efficiente. Un outil ELT profite des capacités natives de Snowflake telle que l'optimisation des charges de travail liées à l'intégration de données.
Caractéristiques du composant Stambia pour Snowflake
Le composant Stambia pour Snowflake permet de se connecter à un entrepôt de données Snowflake de manière simple et rapide. Nativement, Stambia traite l'intégration de données dans Snowflake avec l'approche ELT.
Voici quelques-unes des ses caractéristiques :
Une flexibilité avec n'importe quelle plateforme Cloud
Snowflake doit être installé sur une plateforme Cloud (Amazon AWS ou Microsoft Azure). Les données provenant de divers systèmes sources peuvent être mises en zone temporaire (staging) sur des espaces dédiés. Snowflake supporte :
- Amazon S3 Bucket as External Stage (or Named External Stage)
- Microsoft Azure BLOB Storage (or Named External Stage)
- Snowflake Internal Stage
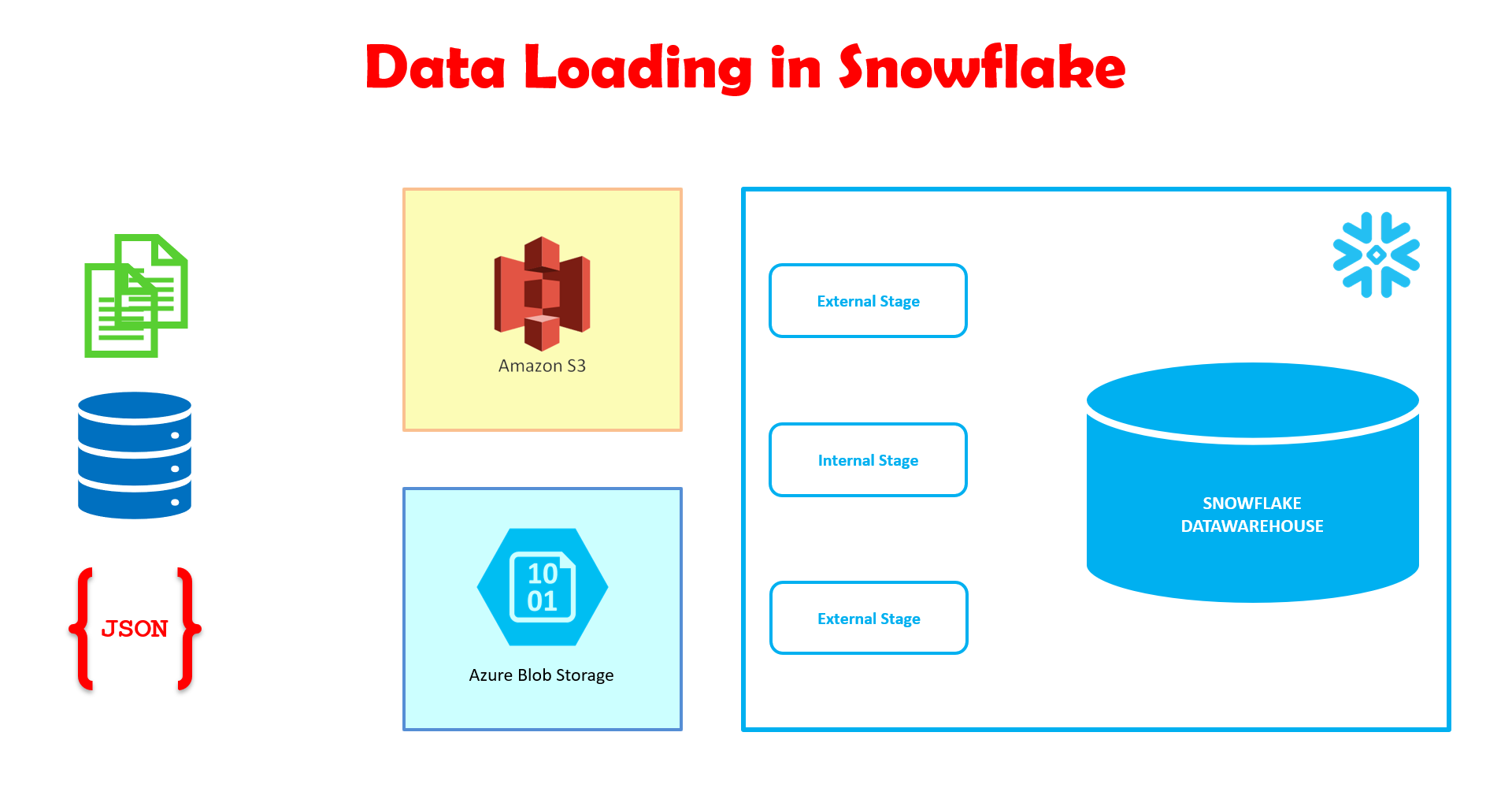
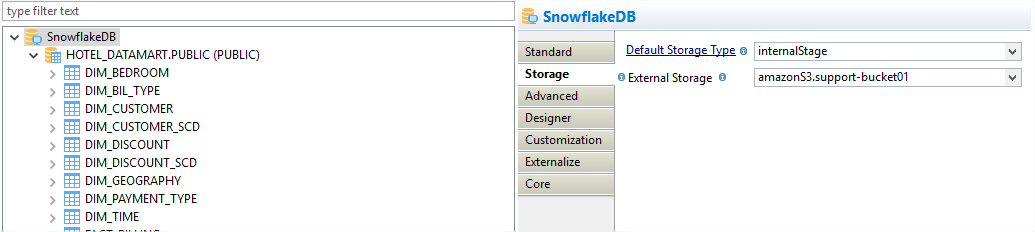
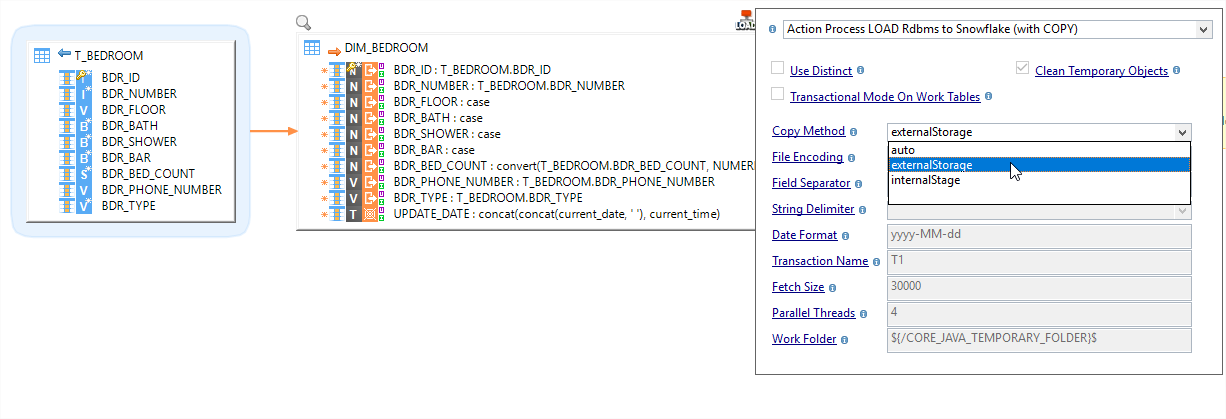
Le composant Stambia pour Snowflake permet à l'utilisateur de sélectionner le type et l'emplacement de l'espace de stockage externe directement au niveau de la méta-donnée. Gain de temps et de productivité : pour l'espace de staging, le Mapping utilise directement ce qui est défini au niveau de la méta-donnée.
Une conception unique autour du Mapping Universel
Pour traiter les différents besoins d'intégration, l'un des points clés de Stambia est le Mapping Universel. Stambia permet de concevoir de manière unique et visuelle des Mappings quelques soient les technologies en source pour alimenter Snowflake.
La conception d'un Mapping est rendue très facile grâce à l'utilisation de "Templates" spécialement conçus pour Snowflake. L'utilisateur se concentre sur les règles métier à appliquer lors du déplacement des données vers Snowflake, les Templates s'occupent de générer et d'exécuter les commandes spécifiques (scripts, SQL) pour alimenter Snowflake.
Le développeur de flux d'intégration de données gagne en productivité. Il n'a plus besoin de programmer toutes les étapes redondantes et les étapes intermédiaires nécessaires. Par ailleurs, il est très facile de changer la zone temporaire (staging) directement au niveau du Mapping ou au niveau de la méta-donnée.
Une migration rapide de vos données On-premise
La migration des données évoquée ci-dessus est le point de départ d'une mise en œuvre d'un Data Warehouse basé sur Snowflake. Le Template de réplication "Stambia Replicator" adapté à Snowflake permet de migrer les données uniques ou historiques d'un entrepôt de données On-Premise vers Snowflake. Grâce à "Stambia Replicator", le processus de génération des flux d'intégration est totalement automatisé.
Les Templates de réplications fournis par Stambia augmentent la productivité. Ils sont complétement personnalisables et permettent d'adapter la migration en fonction de la stratégie établie. Ainsi, il est possible de sélectionner les données à migrer, d'effectuer des conversions, des rapprochements ou tous types d'opérations spécifiques.
Pour en savoir plus sur la migration de données, découvrez notre vidéo sur notre outil de réplication de données "Replicator tool" :

Une maîtrise de la trajectoire projet et des coûts
L'un des facteurs clés dans le choix d'une solution d'intégration de données - notamment pour un environnement scalable comme Snowflake - est le coût de possession (TCO). Avec son approche ELT, Stambia ne nécessite pas d'infrastructure dédiée, les exécutions ne sont pas restreintes à un environnement. Enfin, le coût n'est pas basé sur un volume de données ou une notion de puissance machine. Ainsi, Stambia offre une compréhension simple et lisible du coût de possession.
Stambia est une solution unifiée qui permet de traiter tout type de projets d'intégration de données. Grâce à Stambia, il n'est plus nécessaire de choisir une nouvelle solution à chaque évolution d'architecture ou nouveau besoin métier. Par ailleurs, les composants de Stambia sont simples à comprendre et à utiliser ce qui confère une courbe d'apprentissage rapide. Stambia assure une parfaite maîtrise de la trajectoire des projets nécessitant de l'intégration de données !
Spécifications et pré-requis techniques
| Spécifications | Description |
|---|---|
|
Protocole |
JDBC, HTTP |
|
Données structurées et semi-structurées |
XML, JSON, Avro (à venir) |
|
Stockage |
Type de stockage pris en charge pour stocker des fichiers temporaires en vue d'optimiser les performances :
|
| Connectivités |
Vous pouvez extraire les données de :
Pour en savoir plus, consultez notre documentation technique |
|
Caractéristiques standard |
|
| Caractéristiques avancées |
|
| Version du Designer Stambia | À partir Stambia Designer s18.3.1 |
| Version du Runtime Stambia | À partir de Stambia Runtime S17.3.0 |
| Notes complémentaires |
|
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources



Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :

Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration