
Stambia pour les bases de données relationnelles (SGBDR / RDBMS)
Stambia fournit des composants spécifiques pour tous les types de bases de données relationnelles.
À l'aide de ces composants, vous pouvez accéder aux bases de données pour lire, écrire et effectuer des transformations complexes.
Grâce à son mapping Universel, Stambia vous aide à créer des pipelines d'intégration qui produisent des scripts SQL natifs spécifiques aux technologies.
Bases de données relationnelles: cas d'usage & prérequis
Utiliser une approche ELT pour maximiser les performances
Les ETL, à l'époque, étaient nécessaires en raison de l'incapacité du moteur de base de données à effectuer des transformations complexes.
Les bases de données relationnelles au fil des années se sont améliorées de plusieurs manières: par la fourniture de fonctionnalités plus optimisées à la gestion de gros volumes de données, et par l'apport d'opérateurs complexes sur ces ensembles de données.
Par conséquent, le moteur de base de données est plus performant que jamais.
Travailler avec des SGBDR analytiques avancés nécessite l'appel d'outils de chargement natifs, l'utilisation des fonctions avancées et spécifiques de ces bases de données.
Avec un moteur de base de données amélioré et robuste, l'adoption actuelle des pratiques ELT améliore les performances et offre une plus grande flexibilité dans la mise en place de pipelines d'intégration: Traitements parallèles natifs et robustes, manipulation de types de données plus récents JSON, SPATIAL, CSV, etc.
Et de nombreuses autres fonctionnalités peuvent être exploitées dans la construction des développements d'intégration.

Approche universelle mais pourtant spécifique à chaque technologie de base de données
Le système d'information de chaque organisation utilise au moins un système de gestion de base de données relationnelle (SGBDR) pour prendre en charge leurs données d'entreprise.
Ces bases de données peuvent prendre en charge une application ou peuvent être utilisées comme entrepôt de données (data warehouse) à des fins d'analyse et de reporting.
Dans certains projets, les SGBDR ont été utilisés pour prendre en charge une architecture telle que les Data Hub.
Avec les systèmes d'information utilisant des bases de données relationnelles standard telles qu'Oracle, IBM DB2, Microsoft SQL Server, MySQL, PostgreSQL, etc., il est très important de s'adapter à la manière spécifique dont elles fonctionnent.
Par conséquent, une solution générique ne peut pas prendre en charge les besoins complexes.
La solution d'intégration doit fournir des composants dédiés et optimisés pour apporter les meilleures performances.
D'autre part, il est nécessaire d'avoir une approche universelle de gestion des technologies hétérogènes pour garder les développement simples et industrialisables.
Quelques exemples de projets Cloud réalisés avec la solution Stambia
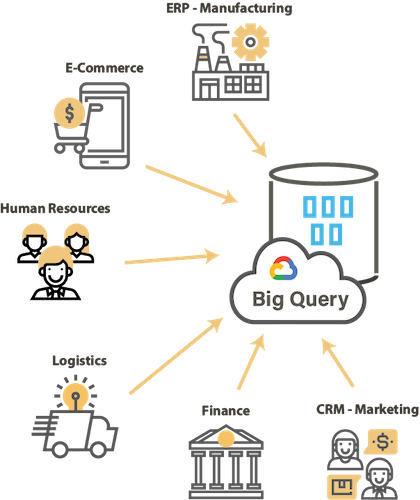
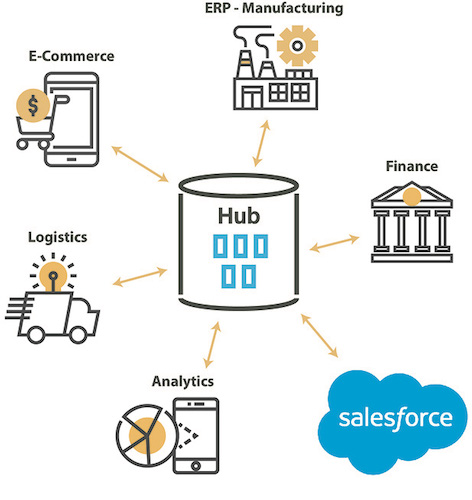
Une solution hybride pour les bases de données en service dans le cloud
Avec l'avènement et l'adoption du cloud, de nombreuses bases de données relationnelles sont disponibles sur le marché et sur les "market place" du cloud.
Ces bases de données offrent les mêmes fonctionnalités avec un modèle de paiement à l'utilisation / usage. Migrer les données vers ces bases de données cloud, intégrer les données quotidiennes de divers systèmes sources vers une base de données cloud, travailler sur un modèle hybride avec des bases de données sur site ou sur cloud, etc. devient une norme.
Dans de tels projets, il est essentiel d'avoir une solution unique, hybride et capable de répondre de manière cohérente aux différents besoins sur site ou sur le cloud.
L'agilité et la maîtrise des coûts sont également des points clés dans les architecture hybrides..

Fonctionnalités du composant Stambia pour les bases de données relationnelles
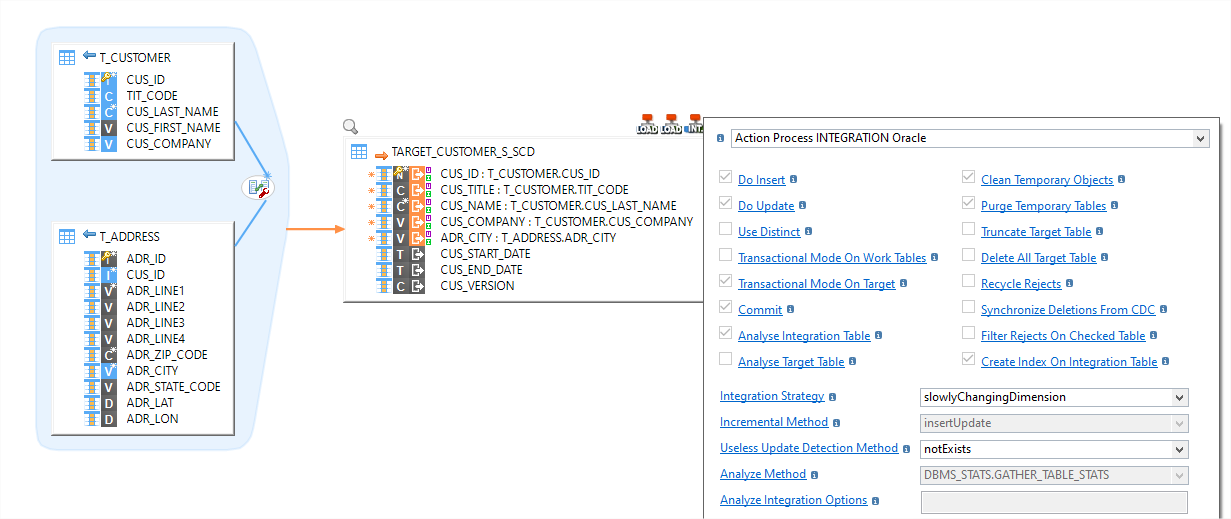
Le composant Stambia pour les bases de données relationnelles offre la possibilité de travailler avec une ou plusieurs technologies SGBDR et d'accéder, d'extraire, de charger et de transformer des données dans et hors de ces bases de données.
Ces composants automatisent et industrialisent une grande partie du développement car l'ensemble des étapes techniques nécessaires est rassemblé dans des modèles techniques appelés "templates".
Par exemple, un même mapping pourra, sans aucun changement complexe, passer d'une mode d'intégration incrémental (update/insert/delete) à un mode historisé (dimensions à évolution lente), ou d'activer l'intégration en mode CDC (Change Data Capture) ou encore de mettre en place la gestion de la qualité de données.
Stambia utilise JDBC comme moyen standard de se connecter aux bases de données. JDBC permet un accès natif à toutes les bases de données sans avoir besoin d'installer de connecteur ou d'API client de base de données.
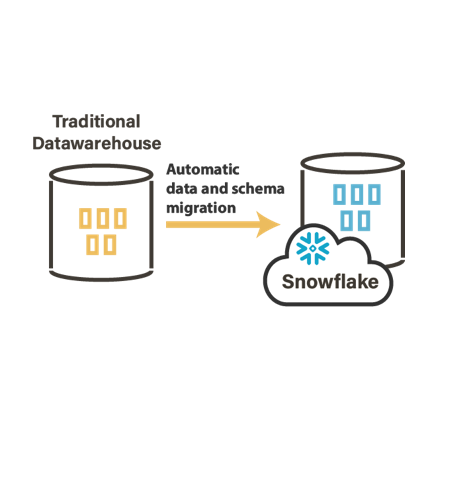
Une approche ELT pour utiliser les fonctions natives et optimisées des bases de données
Stambia met en œuvre les principes ELT, afin de fournir le meilleur niveau de performance sur les bases de données. L'approche E-LT Stambia consiste à faire les transformations sur les systèmes sous-jacents sans ajouter de moteur propriétaire.
Les transformations sont effectuées par les bases de données ou d'autres technologies (OLAP, systèmes d'exploitation, etc.) en fonction de leurs capacités de transformation.
Stambia utilisera tous les composants natifs des technologies sous-jacentes (tels que les chargeurs de base de données, le CDC natif, etc.) pour maximiser les performances.
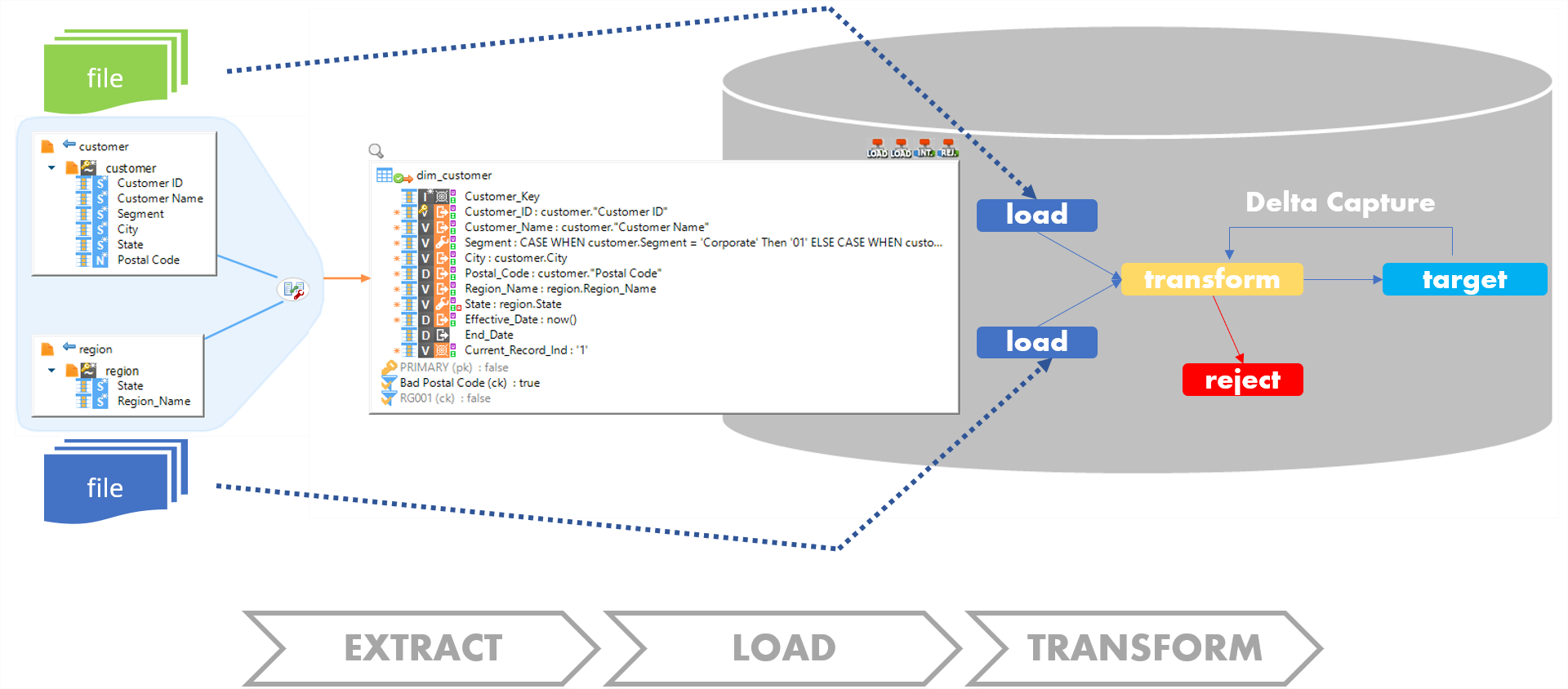
Composant dédié pour chaque technologie avec une manière universelle de développer
Stambia fournit des composants dédiés à chaque type de bases de données relationnelles pour répondre aux différentes spécificités qui existent dans ces technologies.
Les bases de données relationnelles se comportent conceptuellement de la même manière mais sont distinctes les unes des autres syntaxiquement, ce qui signifie qu'une solution générique ne serait pas suffisante pour répondre à toutes les exigences techniques.
Les composants spécifiques de Stambia génèrent du code natif.
Par exemple lorsque vous utilisez Oracle Database comme cible, vous pouvez utiliser SQL Loader ou DBLink. Lorsque vous avez MS SQL Server comme cible, vous pouvez préférer Bulk Load ou BCP.
Avec le mapping universel, les utilisateurs, de différentes équipes et projets, conçoivent d'une manière cohérente et unifiée.
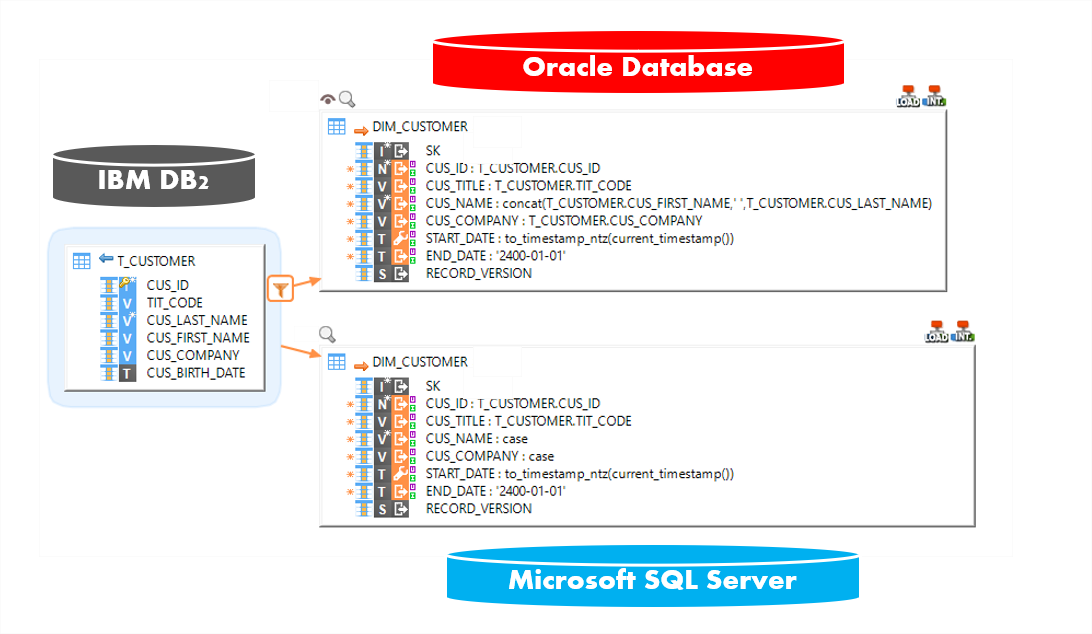
Déployer vos développements et livrables sur tous les environnements

Avec les mêmes composants et en utilisant la même solution, grâce au mapping universel, les développements d'intégration peuvent être configurées pour se connecter à une base de données relationnelle sur le cloud (DB-as-a-service) au lieu d'une base de données "on premise".
Avec les "templates" de réplication de Stambia, les données peuvent être facilement migrées vers le cloud.
Et les mêmes mappings de données peuvent être rapidement configurés pour pointer vers l'instance cloud.
Les processus d'intégration de données peuvent alors être déployés sur le "Stambia Runtime" qui est un composant hybride pouvant être installé n'importe où.
Cela augmente la productivité et l'agilité de vos projets.
De plus, vous pouvez optimiser le coût global de transfert de vos données vers le cloud grâce à la notion de templates et avec une approche ELT.
Vous gérez et optimisez les transformations et les calculs sur le cloud.
Technical specifications and prerequisites
| Spécifications | Description |
|---|---|
|
Protocoles |
JDBC, HTTP |
|
Structured and semi-structured |
XML, JSON, Avro |
| Standard Features | A partir de Stambia Runtime S17.5.6 |
|
Stambia Runtime Version |
Stambia DI Runtime S17.4.7 or higher |
| Liste non exhaustive des technologies prises en charge |
RDBMS: Autres bases: Base de données MPP: Base de données vectorielles ou In Memory: Bases de données Cloud: Hadoop: |
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources




Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration