Cloud, Data Lake, Big Data, IA, Streaming, devops, protection des données et sécurité… ces évolutions opérées ces dernières années dans nos systèmes d’information ont eu un impact fort sur les architectures de données.
Dans ce contexte, l’intégration de données doit, elle aussi, opérer sa révolution. Il se peut que vous utilisiez encore un ETL traditionnel.

Vous pilotez alors un homme-orchestre, impressionnant et efficace dans son domaine, mais disposant d'un nombre d’instruments et une capacité limités.
L'ETL est au cœur du système et doit se plier aux nombreuses exigences et aux évolutions incessantes.
Son agilité est mise à l'épreuve, son coût challengé.
Le constat est de plus en plus unanime : la plateforme d’intégration du Chief Data Officer, ou de son équivalent, doit désormais s'apparenter à un chef d’orchestre plutôt qu'à un homme-orchestre.
L’objectif n’est pas de tout faire soi-même, mais de coordonner intelligemment les ressources disponibles, et de les optimiser.
Cette série d'articles (celui-ci est le premier) aura pour objectif de comprendre les enjeux de l'intégration de données aujourd'hui, et de mesurer les impacts sur la manière dont une solution doit désormais opérer la donnée.
ELT versus ETL, un vieux débat clos depuis longtemps ?

Vous vous souvenez peut-être du débat ELT versus ETL apparu dans les années 2000.
Il est encore possible de consulter sur Internet et dans la presse des traces de ce type de débat, dont voici par exemple un article de BFM TV de 2005 expliquant les mérites d'une solution française de l'époque.
Lorsque sont apparus les premiers ETL (Extract Transform & Load), il y avait déjà les premiers contestataires, partisans de la ligne de code, prônant corps et âme que rien ne valait un bon script écrit à la main.
Ce clivage reste d'actualité et vous rappelle peut-être quelques discussions houleuses mais encore actuelles sur bien d'autres sujets que celui de l'ETL ? 😉
L'outil ETL s'est cependant rapidement imposé comme une évidence.
Il permettait d'industrialiser et de standardiser les processus d'intégration de données à l'échelle de toute l'organisation et de faire abstraction du Système d'Information existant en proposant un langage unique de transformation.
Mais assez rapidement, dans certaines configurations, le volume de données manipulées a imposé à certains utilisateurs, puis à certains éditeurs, de proposer une alternative aux moteurs ETL.
Cette alternative consistait à déplacer le lieu de transformation des données vers la cible sans utiliser un moteur propriétaire pour la transformation.
C'est la fameuse approche ELT (Extract Load and Transform).
Dans cette approche, les données sont chargées dans la base de données cible, puis transformées et contrôlées dans la cible, et non plus dans un moteur intermédiaire.
La transformation est déplacée du moteur vers les systèmes de base de données. Le recours à ce type d'architecture est, encore aujourd'hui, largement dominé par le besoin de performance.
Chaque approche ayant ses avantages, on aurait pu croire ce débat clos depuis longtemps.
Tout comme dans le monde du matériel, il y a ceux qui sont Mac et ceux qui sont PC, dans le monde de la data, il y a ceux qui sont ETL et ceux qui sont ELT. Débat clos. A chacun son approche.
Mais c'était sans compter sur les évolutions opérées ces dernières années dans nos Systèmes d'Information.
Le débat n'était clos qu'en partie, attendant la première occasion pour ressurgir de plus belle.
- Que s'est-il passé?
- Quelles sont les évolutions qui ont suscité une nouvelle forme de débat autour de la transformation ?
- Premièrement, l'émergence du Cloud et des projets Big Data.
L'architecture Cloud et le Big Data remettent la balle au centre
L'architecture Cloud et le Big Data remettent la balle au centre, et ce pour plusieurs raisons.
Selon le Gartner, "d'ici 2022, jusqu'à 60% des organisations utiliseront des offres de services gérés dans le cloud par un fournisseur de services externe, soit le double du pourcentage par rapport à 2018" *source
Cela implique de nombreuses évolutions dans l'architecture globale du Système d'Information et, en conséquence, des flux de données.
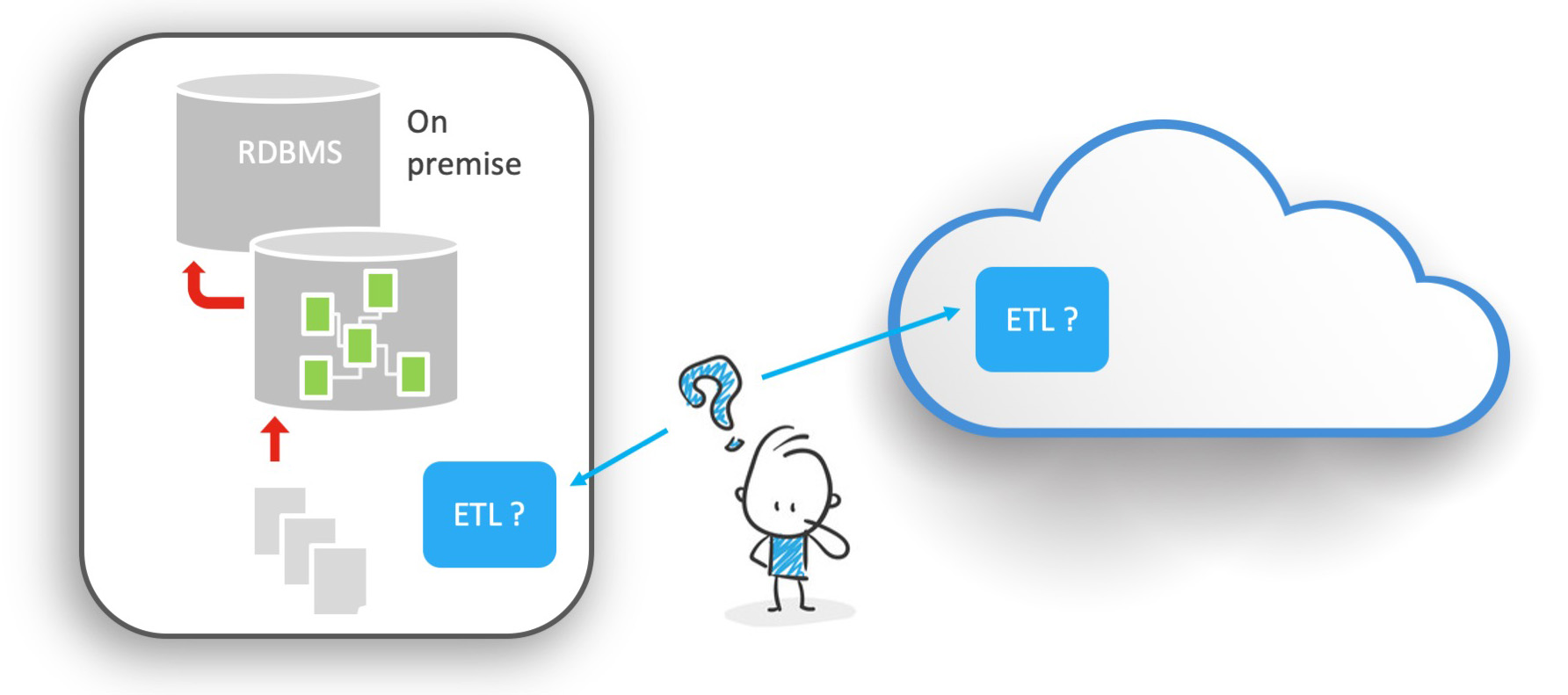
En premier lieu, le Cloud pousse à une décentralisation des infrastructures, et surtout, des données.
Il n'est pas rare de voir émerger des systèmes d'information de plus en plus éclatés, avec des composants sur site (on premise) et des composants dans le Cloud. L'approche SAAS a emmené de nombreuses organisations vers un silotage toujours plus important de leurs applications.
On pourrait presque penser que le Cloud a tué l'ERP traditionnel, ou que ce dernier ne joue plus une place aussi centrale dans les systèmes…. Mais c'est un autre débat, peut-être pour un autre article.
Le constat est, lui, sans appel : Le SI des années 2020 est massivement décentralisé !
La donnée est dispatchée dans des silos applicatifs, répartie de par le monde.
On comprend que dans cette situation, l'usage d'un moteur de transformation, par son essence même centralisé, pose une première question :
où va-t-on mettre le moteur ? Doit-il être "on Premise" ? Doit-il être dans le Cloud ?
Et le positionner dans le Cloud ne fait que déplacer le problème et pose une autre question : mais dans quel Cloud ?
Nous parlons aujourd'hui de systèmes multi-cloud ou de Cloud Hybride ! Il n'est pas inhabituel de voir cohabiter, au sein d'une même organisation, des composants Google, avec des Clouds privés, et quelque part ailleurs des applications SAAS propriétaires.
Une vraie question d'architecture se pose, et derrière cette question, des problématiques de sécurité et de coûts qui sont loin d'être négligeables.
Dans ce contexte, une approche sans moteur de transformation (ELT) se positionne alors à nouveau en alternative.
De fait, elle supprime la question, à la fois d'architecture et de coût!
Egalement, le choix de positionner une application ou une solution logicielle dans le Cloud implique au moins deux besoins immédiats : il sera nécessaire de migrer le patrimoine données vers cette nouvelle application Cloud, puis il faudra intégrer de manière fiable et efficace cette nouvelle application avec le reste du système d'information.
Se posent alors de nouvelles questions : est-ce que je continue à utiliser ma solution ETL ou EAI traditionnelle ? Est-elle compatible? Est-elle suffisante ? Le ROI sera-t-il au rendez-vous ? Ou bien est-ce que j'opte pour une alternative purement cloud ? Je vais alors désiloter mes applications, en les faisant communiquer, mais à un prix : siloter l'intégration de données en ayant plusieurs solutions pour des besoins très semblables!
Là encore, dans cette situation, l'ELT se pose en réelle alternative.
Inutile de déployer quoi que ce soit de nouveau dans le Cloud.
Enfin, en dehors du Cloud, d'autres éléments sont venus bousculer l'architecture des systèmes d'information, et donc, de l'intégration de données : le Big Data, et derrière, implicitement, tous les projets de data science, puis de data ingénierie.
En effet, par définition même, il s'agit de projets de transformation de la donnée. Hadoop, avec son concept de Map Reduce, est une manière de transformer les données. Mais alors, où place-t-on l'ETL dans ce cas ? Quelle est sa valeur ajoutée dans un projet Big Data ?
Spark ou Storm, ce sont là aussi par essence même des moteurs de transformation des données ?
On comprend que, finalement, les algorithmes de traitement du Big Data se substituent naturellement à l'ETL.
Si on voulait résumer le propos : Spark, Google BigQuery, Snowflake, Big Table, Kafka, Flink… chacun de ces outils est parfois mille fois plus puissant que l’ETL que vous utilisiez dans les années 90. Le Big Data a-t-il tué l'ETL traditionnel en le rendant obsolète ?

C’est pourquoi on dû passer de l’homme-orchestre au chef d’orchestre. L’homme-orchestre essayait de tout faire, courait derrière la musique.
Le chef d’orchestre distribue, coordonne et optimise le travail des musiciens de son orchestre.
Considérons la plateforme d’intégration comme un chef d’orchestre, et la puissance des multiples outils de notre système d’information, comme autant d’instruments adaptés à chaque situation
Qu'en est-il de l'ELT ? Il a dû se réinventer mais il est dans son élément, à savoir générer et orchestrer du code : du Java, du Spark, du Python, voire du SQL spécifique à ces environnements.
Sera-t-il alors au rendez-vous pour industrialiser, et maximiser la performance ? Ce sera l'objet de notre prochain article…
Suite de l'article prochainement "La performance et l'industrialisation, les éléments clés de la délégation des transformations"
A propos de l'auteur :

Fabien BRUDER, Co-fondateur de la société Stambia depuis 2009.
Ingénieur informaticien EPITA, spécialisé en intelligence artificielle, diplômé en gestion d’entreprise à l’IAE de Paris.
Après IBS France (intégrateur) puis Sagent (éditeur), il passe 7 années chez l’éditeur Sunopsis (Oracle), en tant que consultant, directeur technique puis directeur d’agence.
Cela fait maintenant 20 ans qu'il travaille en tant qu'expert dans le domaine de l'intégration des données.
